
When a frontier lab evaluates a new model, the benchmarks they choose say a lot about what they value. They reflect not just what a lab considers hard, but what it considers important: the capabilities it wants to invest in, and where it believes the field should be heading.
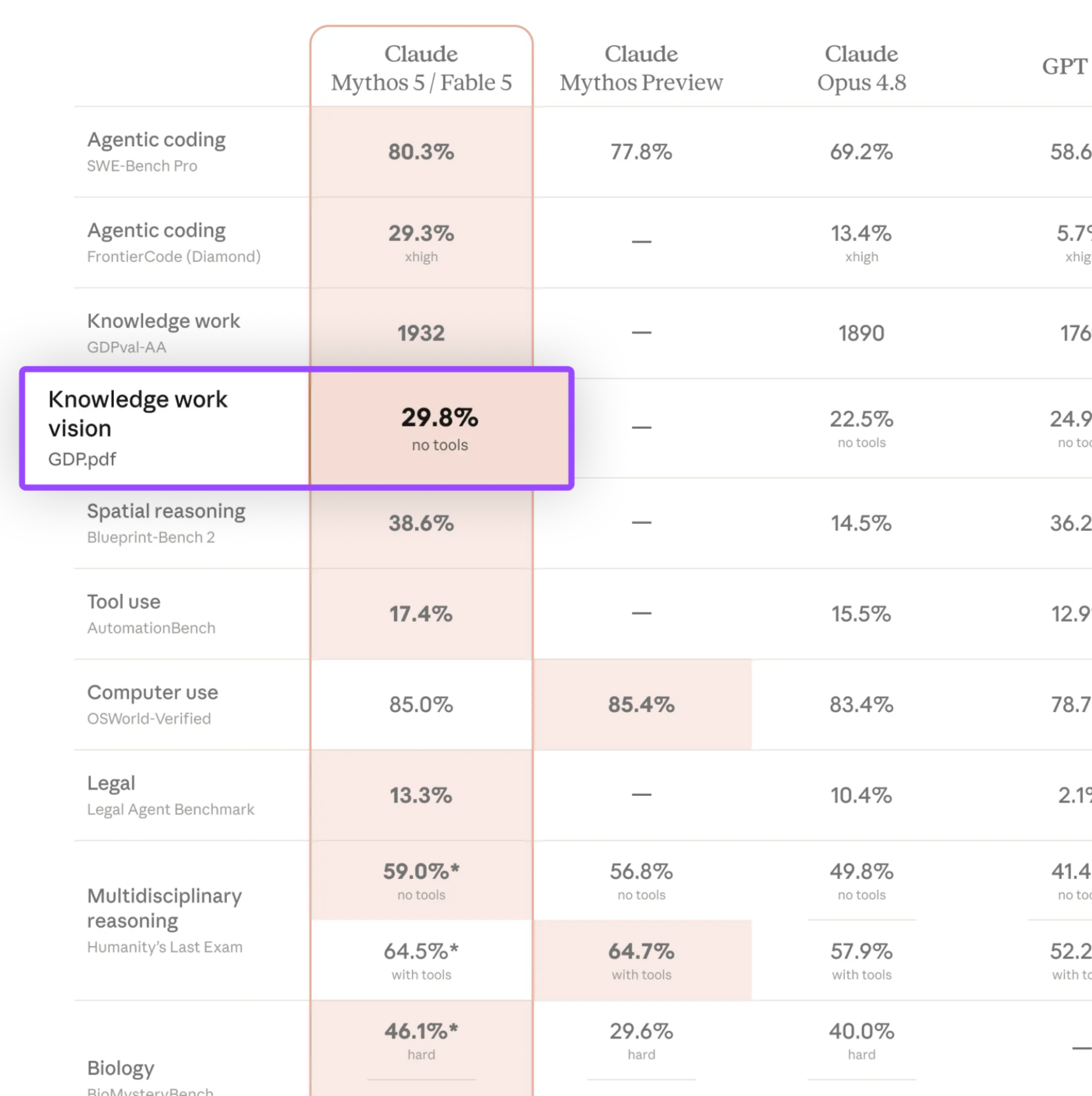
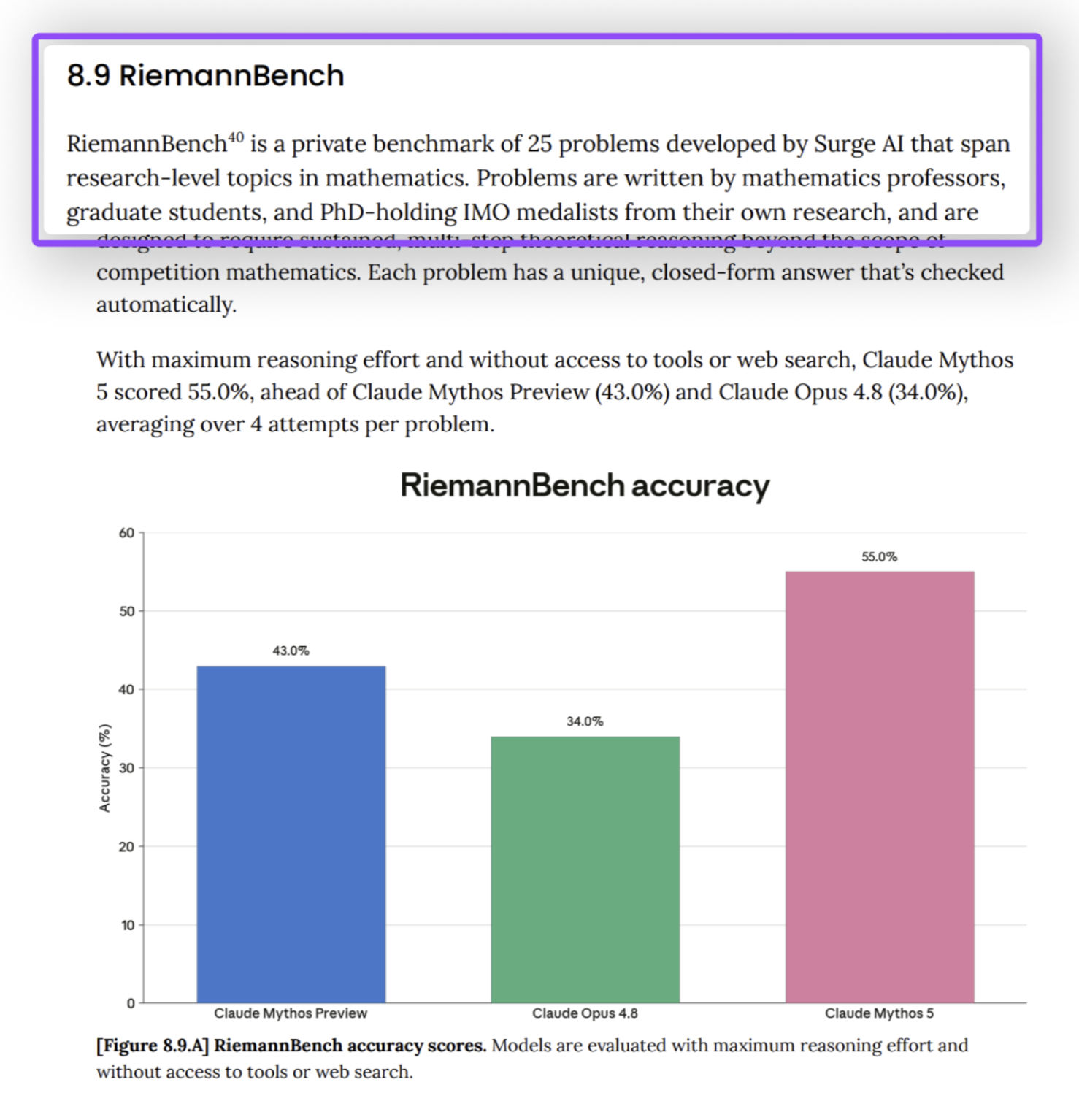
Two of Surge AI's benchmarks appeared in Anthropic's release of Fable 5 and Mythos 5: GDP.pdf, our benchmark for professional multimodal reasoning over real-world documents, and Riemann-bench, our frontier mathematics benchmark, were cited in their system card.
We think this reflects something larger about where model evaluation is heading.
The easy benchmarks are saturated
As models improve, the evaluations that once separated them stop carrying information. Scores cluster near the top, and the benchmark no longer tells you which model is actually better. The evaluations that still discriminate between frontier models are the ones built by people with deep domain expertise: problems hard enough, and graded carefully enough, that a state-of-the-art model can still fail them in ways that teach you something.
GDP.pdf and Riemann-bench point at two of those directions: agents that can handle the documents the economy actually runs on, and models that can do genuine mathematical research.
GDP.pdf: the documents that run the world
GDP.pdf measures professional multimodal reasoning over the documents the economy runs on. It contains real-world prompts and PDFs pulled directly from professional workflows across ten domains: Finance, Healthcare, Legal, STEM/Research, Engineering, Construction, Manufacturing and Supply Chain, Insurance, Real Estate, and HR. Each task requires parsing and synthesizing genuinely complex documents: interpreting a multi-page dosage table, isolating an indemnification clause buried in nested exhibits, reconciling revenue figures across quarterly filings.
These tasks were written by people who do this work for a living: a cardiologist with twenty-five years of clinical experience writing structural-cardiology cases, a Morgan Stanley vice president in private credit writing capital-markets tasks, a Harvard-trained Kirkland & Ellis IP attorney writing licensing and contracts problems. The questions are hard because the people posing them know exactly where a professional's judgment is tested.
It turns out this unglamorous work is still very hard for frontier models: when we first released GDP.pdf, every frontier model scored under 30%. A model that can reason brilliantly in the abstract but loses the thread inside a commercial lease or a drug-interaction chart isn't yet ready for the enterprise work that depends on getting those documents right.
Riemann-bench: moonshot mathematics
Riemann-bench measures frontier mathematical reasoning at the level of real research. We built it with Ivy League mathematics professors, PhD students, and PhD IMO medalists, who contributed problems drawn from their own work, which often the authors themselves weeks to solve. Every problem was verified under a strict double-blind protocol, with two independent experts solving it from scratch.
Even with web search and coding tools available, every frontier model scored below 40% when first released.
Why expert-built evaluations matter
A benchmark that can still challenge a frontier model has to be built by people who operate at that frontier themselves. This is the core of how Surge builds evaluation data: our expert network spans law, finance, healthcare, engineering, and the sciences, and the difficulty of a benchmark is a reflection of their expertise of the people writing it.
This is also why good evaluations matter for the field as a whole. They're how anyone, labs and the public alike, can tell whether models are genuinely improving or just getting better at saturated tests. As the easy benchmarks fill up, the labs that can measure the hard, expert-graded capabilities are the ones that can see where their models actually stand. We build those evaluations, and we're glad to see them used in releases like Fable 5 and Mythos 5.
Work with us
If you're a lab and you'd like to evaluate your models on GDP.pdf, Riemann-bench, or build expert-grade benchmarks in your own domains, reach out to benchmarks@surgehq.ai. You can find Surge's full set of benchmarks on our Leaderboards & Benchmarks page.






