Most instruction-following benchmarks test constraints that are simple and explicit: keep it under 300 characters, use a professional tone, format in Markdown.
Real work isn't like that. The instructions people give come in tangles. Constraints depend on each other, fire only when conditions set by other constraints are met, and sometimes go unstated entirely. The real world contains:
- Conditional constraints. A customer gets automatic refunds if their balance is below a threshold – unless their fraud score is too high.
- Planning constraints. A film shoot schedule has to fit the availability of 5 actors, sufficient daylight for outdoor scenes, travel times, and equipment rental windows.
- Multistep constraints. A reimbursement requires checking the expense category, converting currency at the right exchange rate, applying the company’s per-diem cap, and formatting the result in a quarterly report.
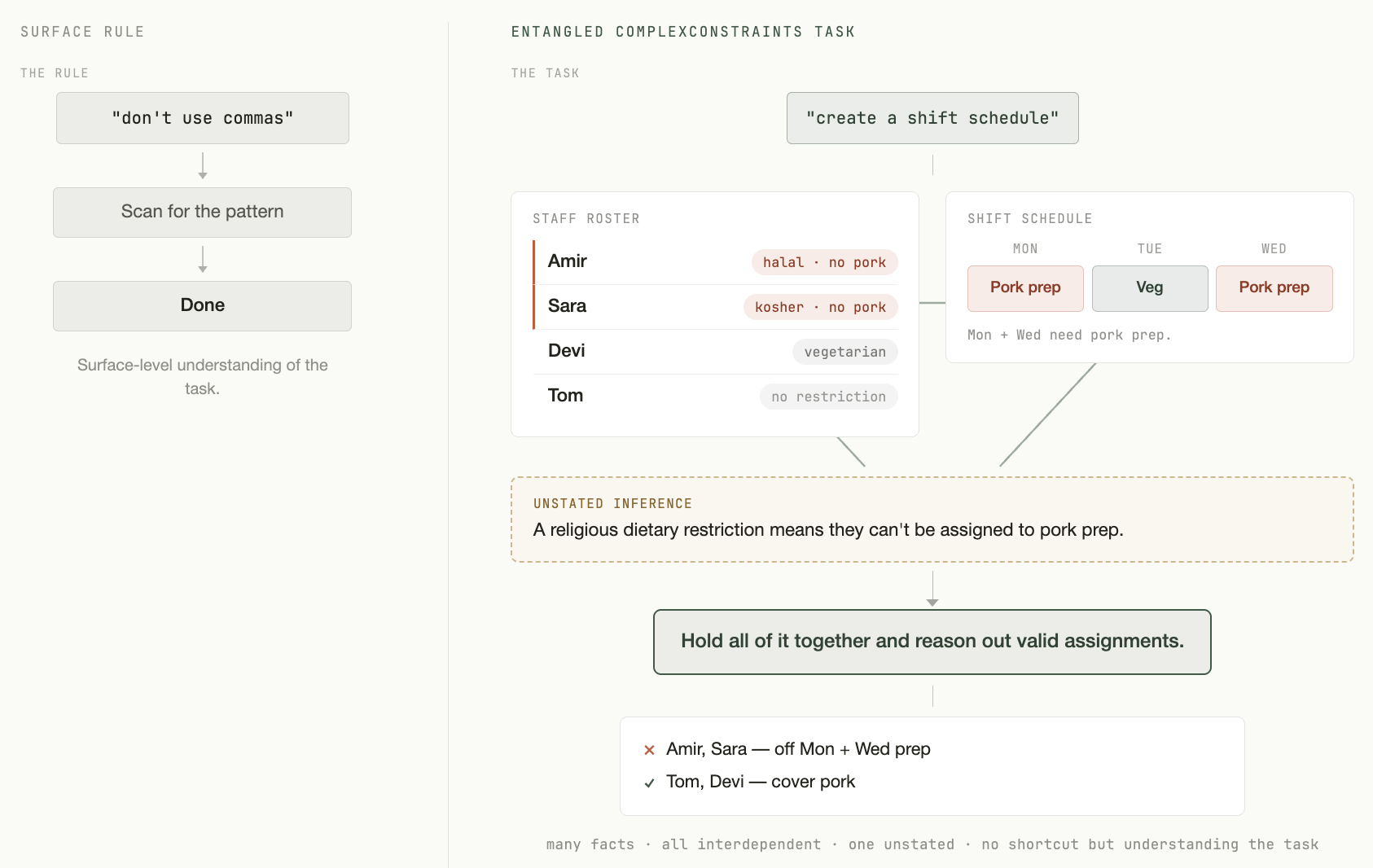
- Implicit constraints. When a restaurant manager asks for a schedule and some staff observe religious dietary restrictions, no one has to spell out that those employees shouldn't be assigned to pork prep.
- Negative constraints. An SEC disclosure has to convey material developments – but can not include forward-looking statements without safe-harbor language or reveal anything that hasn't been publicly filed.
We wanted a benchmark that captures this.
Today we're releasing ComplexConstraints: 75 expert-crafted prompts with 1,559 evaluation rubrics, measuring whether models can do the constraint-heavy work professionals do every day.
Where existing benchmarks fall short
IFEval tests things like avoiding commas or hitting an exact word count. Frontier models score above 80% on it. That's a long way from following the kind of instruction a human professional gives.
AdvancedIF, which we helped the Meta Superintelligence team build, was a step forward: human-written prompts, LLM-as-judge evaluation, rubrics that capture what people care about. But the frontier has largely now mastered the kinds of simple, independent, and explicit constraints that AdvancedIF is composed of.
How ComplexConstraints prompts are built
ComplexConstraints introduces a new level of realistic complexity. Most prompts contain dozens of multi-dependency constraints spanning the following taxonomy:
- Conditional constraints fire only under specific circumstances.
- Planning constraints require finding an arrangement that satisfies multiple constraints at once.
- Multistep constraints require sequential reasoning where each step's output feeds the next; an early error corrupts everything downstream.
- Negative constraints are defined by what the model must not do.
- Implicit constraints are requirements a competent professional would understand without being spelled out.
- It also includes standard explicit constraints (e.g., a specific budget cap, a required exchange rate, a named employee's day off, a specific format).
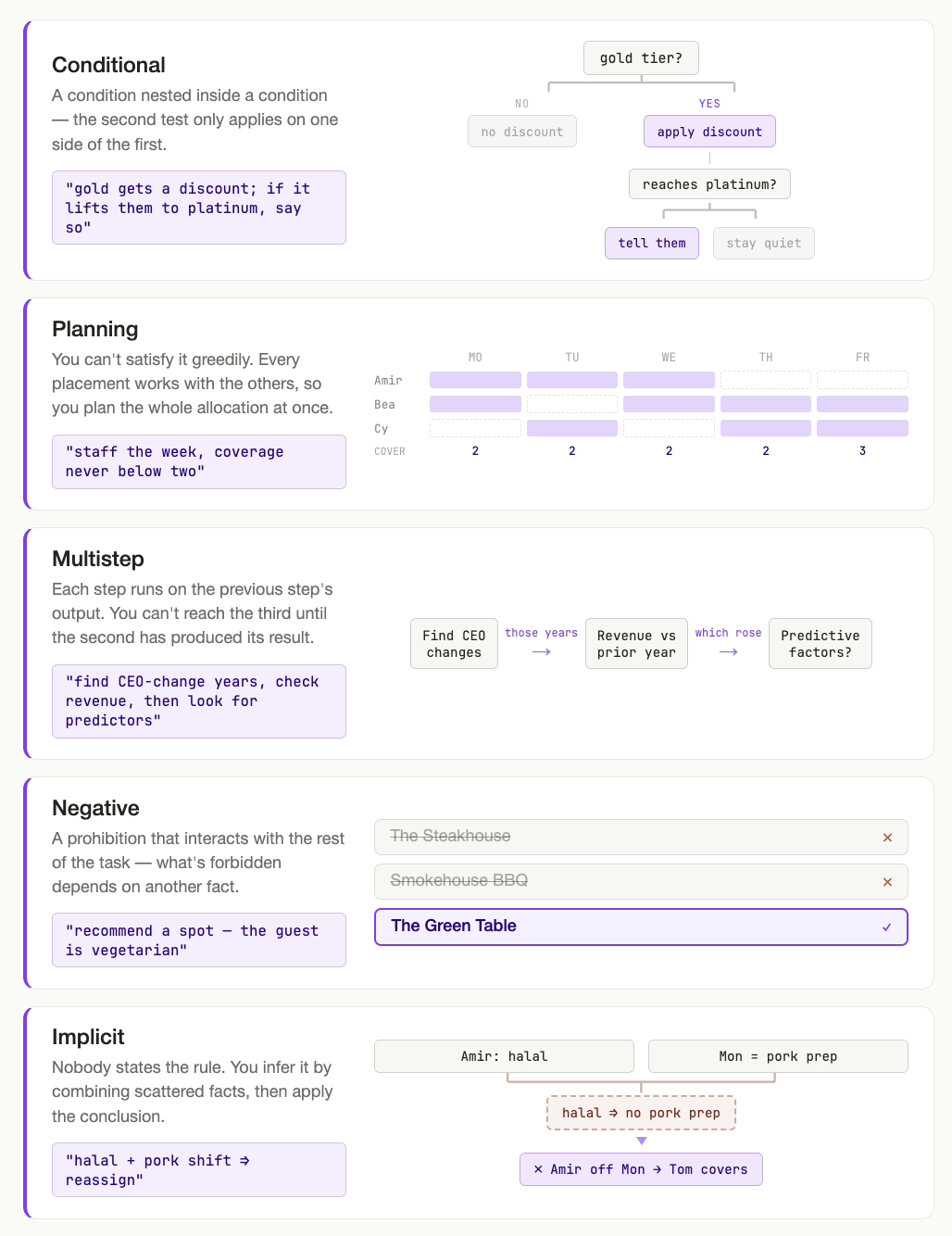
Every prompt comes from day-to-day work: line producers, restaurant managers, teachers, business administrators. Three examples:
- Film production crisis. You're on week 2 of a 5-week feature shoot and four crew members test positive for COVID. Draft a crew memo (2–3 paragraphs, most important info first). Build a contact tracing list using specific exposure criteria (indoor close contact, 60+ minutes). Revise the shooting schedule to move interior scenes to later in the week. Write a formal letter to the bond company. Keep sick crew members' names out of the memo, hold a calm tone, and don't violate union turnaround rules. 33 rubric items.
- Restaurant staff scheduling. An Indian restaurant owner with a diverse staff needs a weekly schedule covering FOH/BOH language requirements, religious restrictions on pork preparation, dishwasher coverage every night shift, extra FOH staffing when training new employees, specific days off per employee, and minimum coverage that varies by shift. 18 interlocking constraints, many of which only matter in combination.
- Office procurement. A team of six needs to outfit a new office on a £3,000 budget: £500 per-person cap (except the boss), standing desks prioritized, one employee with a medical accommodation, desk plants outside individual budgets, output formatted as a draft email to the boss with prices and totals. 30 rubric items spanning budget math, prioritization, and communication.
How frontier models perform
Each prompt has 15-40 rubric items, graded by an LLM judge. Top models score under 40%. View the leaderboard here.

Training on ComplexConstraints companion data
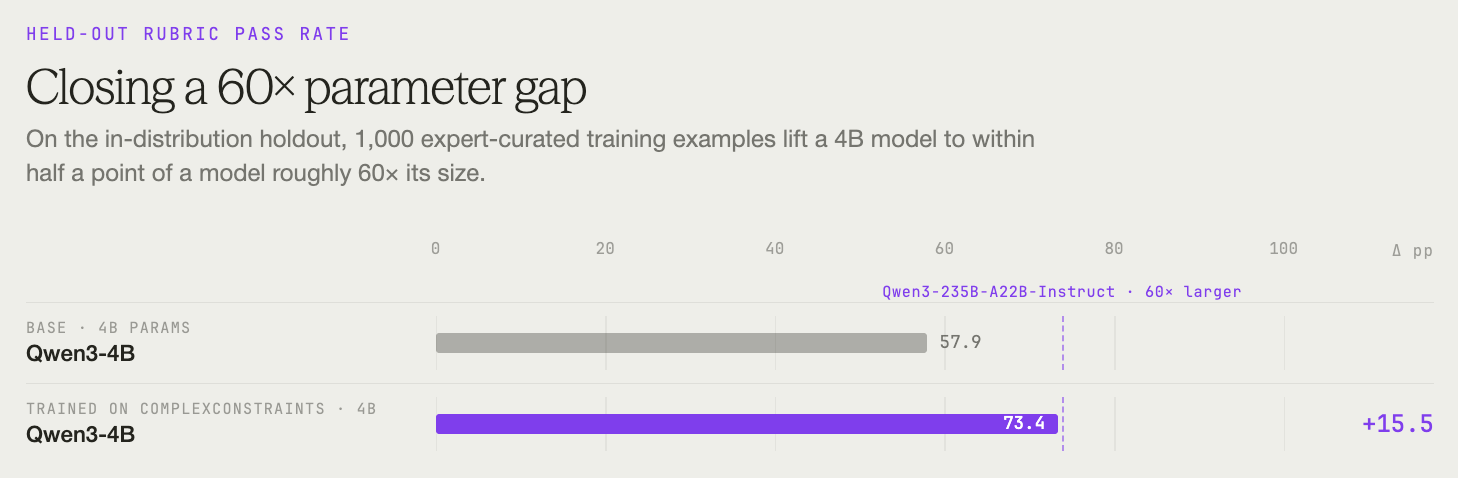
To check whether ComplexConstraints measures something worth optimizing for, we built a companion training set of 1,000 examples, and trained Qwen3-4B using RLVR with a judge model.
On a held-out set, rubric pass rate rose from 57.9% to 73.4% – a 15.5-point gain. The trained 4B model landed at near-parity with Qwen3-235B-A22B-Instruct (73.9%), a model roughly 60x its size.
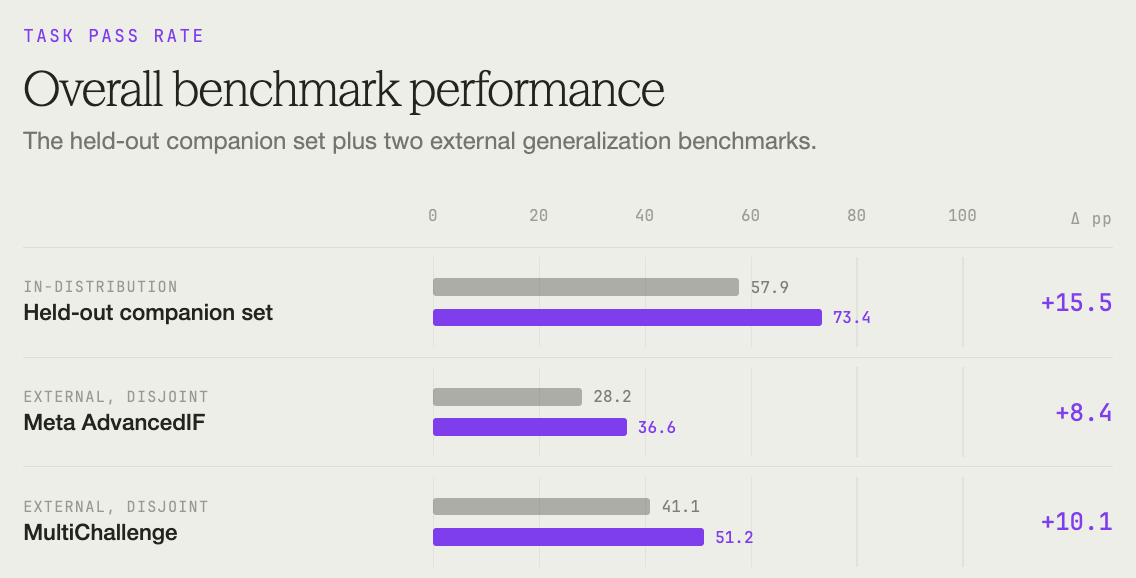
The bigger question is whether those gains transfer.
Do ComplexConstraints gains generalize to other benchmarks?
They do.
On AdvancedIF, overall task pass rate rose from 28.15% to 36.60% (+8.45pp). System Steerability – following behavioral directives in system prompts – jumped 12.42pp. Carried Context, which tests multi-turn instruction retention, improved 7.07pp.
On MultiChallenge, overall task pass rate rose from 41.1% to 51.2% (+10.1pp). Instruction Retention gained 22.1pp, from 23.6% to 45.7%. Self Coherence improved 10.5pp.
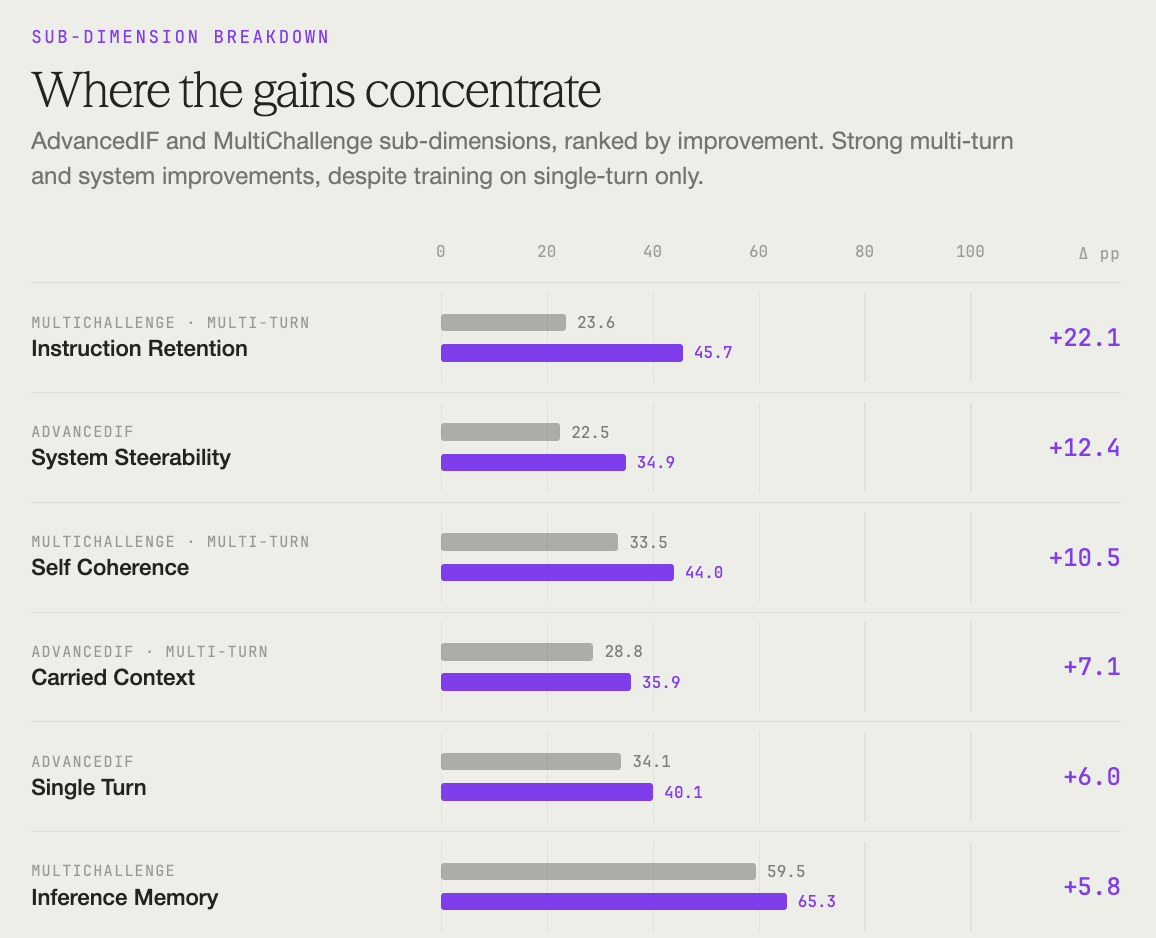
Single-turn training, multi-turn gains
One of the most interesting findings: training on single-turn ComplexConstraints data produced consistent improvements on multi-turn evaluation dimensions in both AdvancedIF and MultiChallenge.
The multi-turn transfer makes sense once you look at the underlying skill. Tracking many simultaneous requirements without dropping the lower-priority ones is the same skill multi-turn IF tests – the difference is just where the requirements come from. In single-turn ComplexConstraints data, they come from earlier in the prompt; in a multi-turn conversation they come from earlier turns. Training on complex single-turn rubrics carries over.
Behavior changes in the ComplexConstraints-trained model
We compared paired runs of the baseline and trained models on the same tasks to understand how the trained model learned to behave differently. A few patterns:
- It stopped dropping hard constraints. On a camp counselor task with 30+ campers and strict rules about sibling separation and medical needs, the baseline ignored the hardest constraints. The trained model processed them systematically: identifying strict limits first, grouping by specialization, and validating group sizes.
- It stopped giving up. On a restaurant scheduling task involving minor labor laws and tight availability, the baseline output "NEED COVERAGE" for every shift. The trained model produced a complete schedule and only flagged shifts where full staffing was mathematically impossible.
- It handled rule-based transformations cleanly. On a sales table task involving unit conversions and conditional formatting, the baseline made errors at nearly every step. The trained model didn't.
- It remembered stated preferences. In multi-turn evaluations, the trained model carried user preferences across intervening turns. The baseline would reason about a preference internally and then fail to surface it in the final answer.
What we want to measure
What a benchmark measures is what models eventually get good at. IFEval rewards letter-counting and formatting tricks, and that's what models learn. ComplexConstraints rewards holding many entangled constraints in mind at once – and the 4B results show that the skill transfers to settings the model has never seen.
That's the kind of complex instruction following that professional work demands.
The full ComplexConstraints benchmark is on HuggingFace here. Leaderboard results are here.






