Read our EnterpriseBench: CoreCraft paper here, and check out the full benchmark
What will it take for AI to actually run a startup?
We aren’t talking about drafting a pitch deck or writing a "we’re sorry" email. We mean an agent capable of triaging a 2 AM server crash or handling a high-value customer who just received a box of broken GPUs.
That’s why we’ve built EnterpriseBench, a suite of RL environment benchmarks designed to evaluate agents on high-value job functions within realistic enterprise companies. We’re launching today with CoreCraft, a high-growth startup that sells computer hardware.
Within this environment, agents aren’t merely answering questions. They must navigate a sprawling graph of 2,500+ entities, parse noisy Slack channels for context, audit shipping manifests against SLAs, and negotiate refunds – all while operating within the red tape of CoreCraft’s company policy.
The Agentic Frontier: Chatbots vs. Chief Operating Officers
So how do we turn AI models from conversational assistants to self-sufficient COOs?
While chatbots are great at writing an apology email, the agentic equivalent is resolving a delayed shipment for an angry VIP customer.
The gap between the two is immense. Real-world agents must solve for:
- Active discovery. Sifting through messy databases rather than having the answer in the prompt.
- Persistence. Managing memory and course-correcting when a tool call returns an error.
- Policy adherence. Navigating the chaos of angry customers and strict enterprise constraints, where wrong moves alienate users and cost real money.
From Sterile Environments to CoreCraft
But if the goal is true autonomy, current RL environments are often too sterile to be useful. They provide the agent with all necessary context in the prompt (eliminating the need for active discovery), operate on static datasets (where actions don't change the world state), or exist in perfect environments where tools never fail.
In contrast, CoreCraft is a large-scale, operational world that forces models to navigate thousands of interconnected entities and do the domain-specific, long-horizon work that real jobs demand.
We built CoreCraft Inc. as a high-performance PC hardware retailer containing:
- 2,500+ entities. A company graph including Slack messages, incomplete records, and customer histories. Agents must actively discover this data since it isn’t provided in the context window.
- 14 entity types. Customers, orders, products, tickets, SLAs, workplace messages, and more.
- 23 unique tools. A diverse stack including search tools, CRM actions, and Slack MCPs. Agents must learn to use these correctly, in combination, and in the right order.
The Benchmark: Frontier Agents Crumble
We designed a suite of customer support tasks within CoreCraft to test frontier capabilities.
Claude Opus 4.6 and GPT-5.2 at high reasoning effort solve around 30% of CoreCraft problems, and only GPT-5.2 at maximum reasoning effort breaks 40%.
These models frequently crumbled in wild, liability-inducing ways: processing hallucinatory refunds, getting stuck in infinite logic loops, and casually leaking PII into the wrong channels.
The CoreCraft Leaderboard
We ran 15 frontier models on the full benchmark. We used a lightweight harness powered by the Vercel AI SDK. Each trajectory was a single conversation turn, but allowed for a tool calling loop of up to 1000 steps. Agents were provided only with the MCP schema and a system prompt describing their role and CoreCraft company policy. Default inference parameters were used for each model unless denoted by parentheses.
Versions of GPT-5.2, and Claude Opus 4.6 occupied the top three places, with Gemini 3.1 Pro just behind – but even with maximum reasoning effort, more than half of CoreCraft problems are unsolved. Other frontier models – like Gemini 3 Flash and Grok 4.1 – scored measurably lower.


Why did models fail?
We analyzed each model's failures to understand what went wrong, from basic hallucinations to complex reasoning errors.
Note: In the following examples, GPT-5.2, Opus 4.6, and Gemini 3 Flash were set to high reasoning effort.
Example Failure #1: GPT-5.2 Fails to Narrow Its Search Window and Gives Up Early
GPT-5.2 was asked to compare motherboards for a customer, including identifying the most popular one:
"I have a customer here, Aiden Mcquarrie. He bought a motherboard in October this year and is looking for a potential replacement... He also wants a comparison of the one he has with the next most expensive motherboard, the absolute most expensive one, and the most popular one (based on the number of fulfilled orders containing each motherboard from the last 2 months)."
Determining the "most popular" motherboard requires counting fulfilled orders per product. The searchOrders tool returns a maximum of 10 results per call, and successful tool-using agents realized that they needed to paginate searches in some form.
GPT-5.2 searched for fulfilled orders for each of the four available motherboards:
searchOrders(
product_id="skyforge-b550m-micro", status="fulfilled",
created_after="2025-10-01", created_before="2025-12-01",
limit=10
) → 10 results (earliest: Nov 9)
searchOrders(product_id="skyforge-x670e-pro", ...) → 10 results (earliest: Nov 4)
searchOrders(product_id="cryonix-z790-apex", ...) → 10 results (earliest: Oct 26)
searchOrders(product_id="voltedge-v9980se", ...) → 10 results (earliest: Oct 20)Every query hit the 10-result cap. GPT-5.2 immediately gave up on this part of the task, uncreatively deciding the problem was unsolvable:
"The tools only let me search orders with a limit of 10 results based on status and date range. This limitation makes it impossible to get a total count across all products, and querying individually won't help either since each still returns only 10 records."
In its final response, GPT-5.2 punts the problem along to another employee!
"For a definitive “most popular” motherboard, please request an internal report from Aisha Khan (Product & Catalog Manager) at akhan@corecraft.com."
In contrast, on the same task, Opus 4.6 managed to find a simple, creative workaround:
"I see all four motherboards hit the 10-result limit. I need to get additional counts to determine the most popular. Let me search for earlier orders that weren't captured."
It paginated by narrowing the date window to fall before the earliest result from each prior batch:
# First batch returned 10 results, earliest dated Nov 9
# Search again for everything before Nov 9
searchOrders(
product_id="skyforge-b550m-micro", status="fulfilled",
created_after="2025-10-01", created_before="2025-11-09",
limit=10
) → 10 more results (earliest: Oct 20)
# Still at the cap — search before Oct 20
searchOrders(
product_id="skyforge-b550m-micro", status="fulfilled",
created_after="2025-10-01", created_before="2025-10-20",
limit=10
) → 1 result (no more data)Agents that give up and escalate at the first sign of difficulty aren't reducing anyone's workload. It's unlikely that Aisha would think this made her job easier!
Example Failure #2: Gemini Guesses an Incorrect Delivery Date and Denies a Valid Return
An employee reported that customer Jillian Reaves had a cooling system issue with her NebulaX Workstation Pro and asked the agent to check the warranty and return status of her order:
"Alex here, I have a ticket from customer Jillian Reaves. . . stating that the cooling system of the nebulax workstation pro prebuild she bought from us isn't starting up. . . Also include the warranty/return status of this customer's order."
The return policy is explicit: "CoreCraft offers a 21-day return window from the date of delivery for all items." The current date in the task is December 1, so any order delivered after November 10 would still be eligible.
Both Gemini-3-Flash and GPT-5.2 called getOrderDetails and received:
{
"shipment": {
"id": "ship-251105-676",
"tracking_number": "1Z999AA789924329",
"carrier": "ups_ground",
"status": "delivered"
}
}Status: "delivered". But no delivery date anywhere in the response. GPT-5.2 figured out that it needed to use the searchShipments tool to retrieve the necessary details:
"The order details tool only says the status is delivered, but it doesn't provide shipment events or a delivery timestamp. . . I think I can use the searchShipments function with the order_id to find the necessary events."
Gemini didn't seem to recognize the gap at all. The model's reasoning states:
"The return window is closed — it expired on November 26th. However, thankfully, the system is still under the 36-month warranty, which is good news for the customer."
And the final email to send to the customer reads:
"Return Eligibility: Your system was delivered on November 5, 2025. As we are now past the 21-day return window (which ended November 26), the system is no longer eligible for a standard return."
Where did November 5 come from? Gemini seems to have mistakenly hallucinated it from the shipment ID: ship-251105-676. The searchShipments call that GPT-5.2 made tells a different story:
searchShipments(order_id="ord-251102-810") → delivered 2025-11-13 Little Rock, ARThe package was delivered November 13, eight days later than Gemini assumed. The return window was still open.
This is a sharp illustration of the challenges for real-world agents. Even as outright hallucinations decline, models remain susceptible to making unjustified assumptions based on partial information. In production, that means a customer entitled to a full return gets denied.
Example Failure #3: Opus 4.6 and GPT-5.2 Use Overly Restrictive Search Queries
CoreCraft's knowledge base search tool uses substring matching. Its text parameter description explicitly states "Substring to match against title and body." This means shorter, simpler terms cast a wider net, while long or overly specific phrases are likely to miss, just like in other enterprise search tools like Slack. We found that even the best models struggled with choosing suitable search terms and widening the search when necessary.
In the same task as example 2, the model is also asked to search the knowledge base for articles relevant to the customer’s ticket:
"Alex here, I have a ticket from customer Jillian Reaves. . . stating that the cooling system of the nebulax workstation pro prebuild she bought from us isn’t starting up. I need you to search the knowledge base for any documented issues related to the nebulax workstation pro, and the cryowave aio unit."
The model retrieved the ticket, which read:
"I received my Nebula X Workstation Pro last week and it was working fine initially. However, it seems the cooling fans haven't been turning on when I start the PC. The system boots up but starts heating up very quickly. I'm worried about damage to the components."
Claude Opus 4.6 tried the following searches:
searchKnowledgeBase(text="Nebulax Workstation Pro") → empty
searchKnowledgeBase(text="Cryowave AIO") → empty
searchKnowledgeBase(text="cooling fan not starting") → empty
searchKnowledgeBase(text="AIO cooling") → empty
searchKnowledgeBase(text="prebuilt troubleshooting") → empty
searchKnowledgeBase(text="troubleshooting cooling") → emptySix queries, all empty. Some of these are reasonable first attempts, but when they returned nothing, the model never simplified. It kept trying variations at the same level of specificity, mixing in descriptive phrases like "cooling fan not starting" that are unlikely to hit a substring match.
Any of the following would have found the relevant article:
searchKnowledgeBase(text="aio") → Complete PC Building Guide
searchKnowledgeBase(text="cooler") → Complete PC Building Guide
searchKnowledgeBase(text="cooling") → Complete PC Building Guide
searchKnowledgeBase(text="fan") → Complete PC Building GuideThese broader terms aren't necessarily the right starting point, but after six empty results, it's time to go wider.
GPT-5.2 exhibited the same pattern on a different task. A customer wrote in:
"Hey, it's Maya Herrera. I bought a monitor from you guys a few weeks ago in November 2025. I just realized that I don't think I'm getting the highest resolution displayed. Is there a trick to it or can I return it?"
The agent identified the product as a ClarityOne 32" 4K 144Hz Pro Monitor and searched the knowledge base:
searchKnowledgeBase(text="monitor resolution") → empty
searchKnowledgeBase(text="display resolution") → empty
searchKnowledgeBase(text="4K monitor") → empty
searchKnowledgeBase(text="refresh rate monitor") → empty
searchKnowledgeBase(text="monitor setup") → empty
searchKnowledgeBase(text="native resolution") → empty
searchKnowledgeBase(text="EDID") → empty
searchKnowledgeBase(text="no 4K") → empty
searchKnowledgeBase(text="monitor not 4K") → emptyNine queries, all empty. Again, the model never broadened its search. Worse, it never tried searching for the actual product name, which was already loaded in context.
searchKnowledgeBase(text="ClarityOne") → ClarityOne User Guide
searchKnowledgeBase(text="resolution") → ClarityOne User Guide
searchKnowledgeBase(text="monitor") → ClarityOne User GuideThe pattern across both models is the same: when their initial searches return empty, they keep iterating at the same level of specificity instead of going simpler. Searching and navigating internal databases is a basic skill for any customer support agent.
Example Failure #4: GPT-5.2 Executes a Conditional Branch That Doesn't Apply
An employee asked:
"Find out if customer Sarah Chen is eligible for a loyalty tier upgrade to Platinum, based on her purchase history as of today. If she isn't, tell me the amount of money she needs to spend before January 2026 in order to reach that loyalty tier, and find a few products or bundles with a price higher than that amount that we can recommend to her in a promotional email. All recommended products should also be compatible with whatever she's bought from us before."
The conditional is clear: product recommendations are only needed if she isn't eligible. Both GPT-5.2 and Claude Opus 4.6 correctly calculated that Sarah Chen had spent $12,083.17 in the last 12 months, well above the $5,000 Platinum threshold. She was already eligible. The task was effectively done.
However, GPT-5.2 kept going. It reasoned:
"Since she's already eligible, the threshold amount is $0, which means I can suggest items priced higher than that."
It then spent 11 additional tool calls searching for GPUs, CPUs, motherboards, monitors, and bundles, running compatibility checks, and composing a full promotional email with product recommendations.
Its final response included a section titled "Promo items you can recommend (priced > $0.00)".
Claude Opus 4.6's reasoning on the same task was much more straightforward.
"Since she already qualifies for Platinum, there's no additional spending target and no need for promotional product recommendations at this time — the priority is getting her tier corrected."
This is easy to catch when going through an employee. But if the agent could send emails directly, loyal customers might receive messages like: "3 products over $0 to help you reach Platinum (you’re already eligible)".
Training on CoreCraft Data
In addition to evaluating the models on the EnterpriseBench benchmark, we trained a frontier-scale model using reinforcement learning on CoreCraft, using the environment's expert-authored rubrics as verifiable reward signals.
The goal of this training is twofold. First, we aim to improve performance on the held-out CoreCraft evaluation set, showing that rubric-based RL training produces measurable gains on challenging agentic tasks. Second, and more importantly, we evaluate whether these gains transfer to external benchmarks that the model was never trained on, testing our hypothesis that high-fidelity environments teach generalizable agentic skills rather than environment-specific heuristics.
We use GLM 4.6 as our base model, a 357B parameter mixture-of-experts architecture with 32B active parameters. We used a random train-test split from the CoreCraft environment with 1000 tasks used for training and 150 tasks in the held-out evaluation test.
Results: In-Distribution Performance
After one epoch of training, GLM 4.6 improves from 25.37% to 36.76% on a held-out eval set (separate from the current benchmark set), a gain of 11.39 percentage points.
Qualitative Analysis of Learned Behaviors
To understand what the model learned, we analyzed paired trajectories comparing baseline and trained model behavior on identical tasks. Three categories of improvement emerged:
1. Multi-Step Workflow Execution
The most significant improvement was in end-to-end execution with correct task decomposition. The trained model follows intended operation sequences: validate constraints, identify incompatibilities, apply fixes, compute totals, present structured output.
Example: A PC build compatibility task requires verifying component compatibility, identifying issues, recommending fixes, and computing updated totals. The baseline performs partial compatibility checks with incorrectly sequenced recommendations. The trained model executes the correct workflow: (1) retrieve order and catalog data, (2) identify case-motherboard incompatibility first, (3) recommend case replacement in correct sequence, (4) compute accurate price totals.
2. Constraint Handling and Reasoning
The trained model significantly improved at applying constraints correctly: filtering data by time windows, handling “before/after'' relationships, and correctly joining records based on ordering.
Example: A task requires finding orders placed after a support ticket creation within a 30-day window with specific status constraints. The baseline retrieves orders but applies inconsistent time comparisons. The trained model uses explicit datetime comparisons, filters to post-ticket orders only, enforces the 30-day window, and produces clean structured output with timestamps.
3. Response Quality and Structure
The trained model produces more complete, actionable outputs aligned with realistic customer communication patterns.
Example: A shipment status email task requires generating professional communication with carrier details and next steps. The baseline produces inconsistent phrasing without clear guidance. The trained model produces structured email with: (1) order reference, (2) current shipment status with carrier name, (3) expected delivery window, (4) clear customer next steps, (5) support contact information.
These three competencies are not specific to PC components or CoreCraft's particular tools, and they help explain the observed transfer to external benchmarks, as discussed in the out-of-distribution results below. Because CoreCraft tasks mirror realistic enterprise workflows, the model learns general professional patterns rather than environment-specific shortcuts.
Results: Out-of-Distribution Generalization
We also present results on benchmarks outside CoreCraft’s training distribution. The trained model shows consistent improvements across long-horizon tool-use benchmarks.
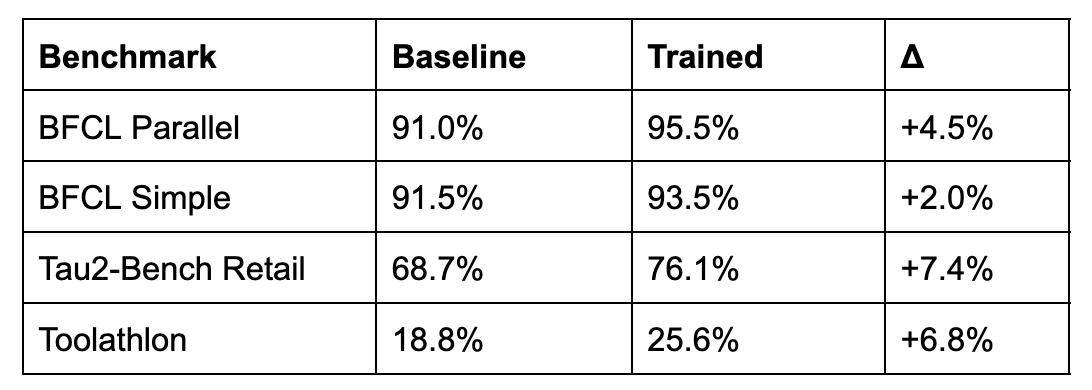
BFCL Results
The Berkeley Function Calling Leaderboard evaluates parallel and simple function calling scenarios. The trained model improves by 4.5% on parallel calls, which require invoking multiple APIs correctly in a single turn, suggesting better tool coordination learned from CoreCraft’s multi-tool workflows.
Tau2-Bench Results
The Tau2-Bench Retail domain evaluates customer service conversations requiring database lookups, policy application, and response generation. The 7.4% improvement demonstrates that customer support skills transfer across different retail contexts.
Toolathlon Results
Toolathlon evaluates language agents on 108 diverse, long-horizon tasks spanning 32 software applications and 604 tools, requiring an average of approximately 20 interaction turns per task. The trained model improves from 18.8% to 25.6% (+6.8%). This is a particularly notable transfer result because Toolathlon tasks (e.g., managing Kubernetes deployments, grading assignments on Canvas, syncing product inventories across databases) are substantially different from CoreCraft’s customer support domain, suggesting that the trained model acquired broadly applicable agentic skills rather than domain-specific shortcuts.
Detailed Analysis: Toolathlon
We also provide a detailed analysis of performance to characterize where and how CoreCraft’s training improves long-horizon agentic capabilities on Toolathlon.
Evaluation Protocol
We evaluated the fine-tuned model on all Toolathlon tasks across 3 independent runs using the Toolathlon private evaluation service. We report three complementary metrics and pass^k formulation: Pass@1 (mean pass rate across runs, measuring expected single-attempt performance), Pass@3 (fraction of tasks passed on at least one run, measuring best-case coverage), and Pass^3 (fraction of tasks passed on all runs, measuring worst-case reliability).
Overall Results
The table below summarizes the aggregate improvements. Pass@1 increases by 6.8 percentage points from 18.8% to 25.6%, with per-run pass rates of 25.0%, 26.9%, and 25.0%, indicating high stability across runs. The reduction in standard deviation from 2.2% (baseline) to 0.6% (trained) also reflects more consistent performance. Pass^3 nearly doubles from 9.3% to 17.6%, indicating that the trained model not only solves more tasks overall but does so more reliably: 19 tasks (17.6%) are solved consistently across all 3 runs, compared to 10 (9.3%) for the baseline.
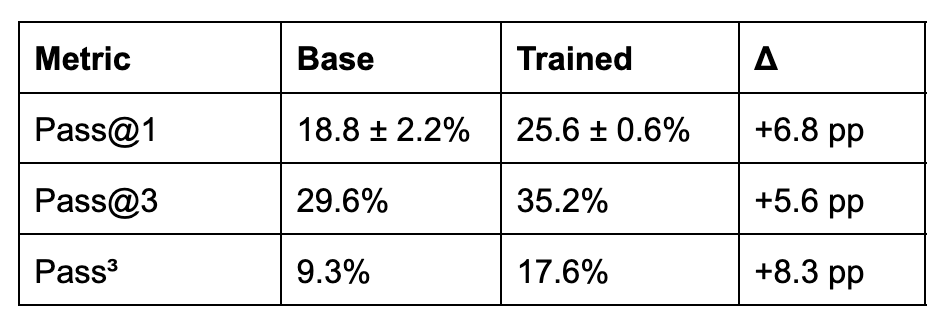
Summary of Training Results
The strongest performance appears in Data Analysis/Finance and Web/Forms/Documents, while Monitoring/Operations and Notion remain more challenging.
The Toolathlon results provide several insights about the nature of transfer from CoreCraft training:
- Gains are broadest in categories that share structural properties with CoreCraft tasks (multi-step data retrieval, constraint satisfaction, structured output generation). This is consistent with our hypothesis that CoreCraft teaches generalizable workflow patterns rather than customer-support-specific domain knowledge or heuristics.
- The near-doubling of Pass^3 suggests that training improves not just peak capability but also reliability, an outcome particularly relevant for production where consistency matters more than occasional success.
- The headroom in Monitoring/Operations and Notion tasks highlights that certain capabilities may require targeted training environments, motivating future work on multi-domain curricula.
More details on methodology and training parameters can be found here.
What Comes Next
This is the first release in the EnterpriseBench family. We are building environments for additional job families, each introducing new toolsets and state complexities. The goal is to build evaluation environments that reflect the actual entropy of the real world.
Read our EnterpriseBench: CoreCraft paper here, and check out the full leaderboard.






