
As LLMs push deeper into professional domains, we decided to measure them on one of the biggest opportunities: finance.
Our finance experts – former traders, investment bankers, and risk managers with decades of experience – built 200+ scenarios across seven finance subcategories. We evaluated the latest frontier models on everything from Basel capital calculations to commodities trading to PowerPoint and Excel manipulation.
The Verdict
All three models showed impressive sophistication. But all three also fell into systematic failure modes – from calculation accuracy to regulatory compliance, and even basic file handling – that reveal where they still lag behind financial professionals.
Overall Performance
GPT-5 > Claude > Gemini
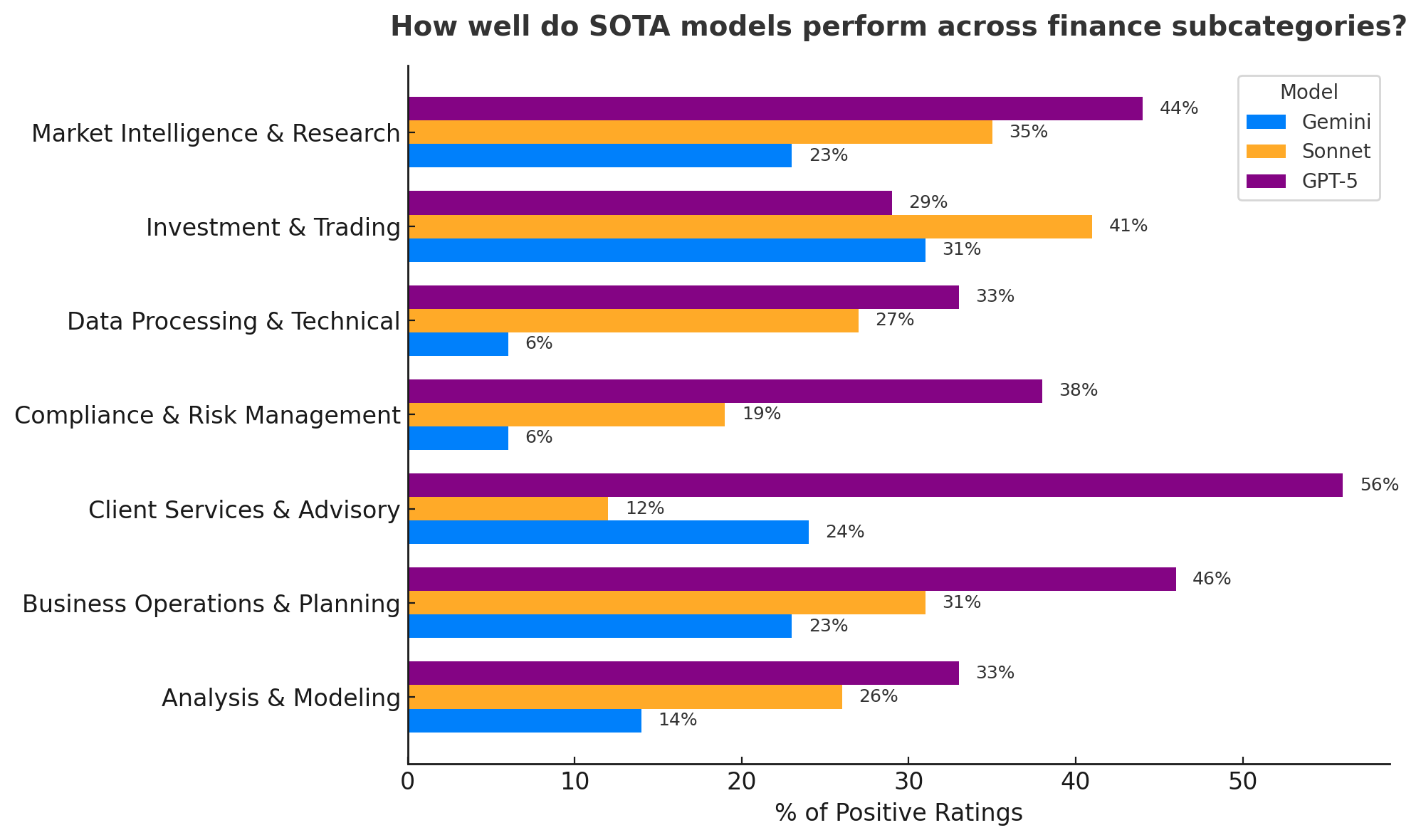
Overall, GPT-5 was the clear favorite on 47% of finance tasks, outperforming Sonnet 4.5 (26%) and Gemini 2.5 Pro (24%).
.png)
When pitted head-to-head, GPT-5 won over Sonnet with a 59% vs. 36% win rate, GPT-5 won over Gemini with a 62% vs. 35% win rate, and Sonnet won over Gemini with a 52% vs. 41% win rate.
.png)
GPT-5 led in six out of seven financial domains, outperforming Claude Sonnet 4.5 and Gemini 2.5 Pro. Sonnet occasionally pulled ahead in trading and execution scenarios.
But leadership doesn’t equal competence.
When our expert finance Surgers scored each model holistically, the verdict was blunt:
Over 70% of responses fell in the mediocre to bad range.
Even GPT-5’s best attempts showed persistent blind spots in reasoning and real-world process alignment.
As one Surger, Carla – a Finance and Operations Manager experienced in multi-grant budgeting and regulatory documentations – put it:
"Overall, GPT would confuse financial analysts more than it would help them with this document."

So the biggest question: where do the models fall short?
Six Financial Loss Patterns
After digging into the eval, we saw the same six loss patterns appear again and again:
- Reasoning from Theory Without Real-World Constraints
Models often solved problems as if they were academic exercises, ignoring the messy constraints that define real markets. They applied formulas correctly but missed the operational realities that make those problems hard, like liquidity freezes, regulatory boundaries, or trading-limit conditions. In the Basel case we'll highlight later, all three models treated risk offsetting more simply than regulations permit, applying theoretical netting logic beyond regulatory boundaries.
- Breakdown in Multi-Step Workflow Execution
The models could follow individual instructions, but consistently lost coherence when they had to connect multiple dependent steps or sustain logic over a longer workflow.
- Weak Domain Calibration
All three models lacked professional “gut sense.” They produced assumptions that looked numerically clean but contextually absurd: shocks that were too mild for real crises, portfolios that all lost the same amount, or hedging strategies that ignored instrument liquidity.
- File Handling and Output Fidelity
In finance, deliverables matter as much as reasoning. Here, models routinely failed to handle files reliably: breaking formulas, misreading inputs, or returning unusable downloads.
- Missing Implicit Professional Conventions
Financial analysis depends on unstated norms: how metrics are signed, how mark-to-market terms are included, how templates are formatted. Models frequently skipped or inverted these conventions, producing outputs that looked correct but violated professional expectations.
- Framework Misalignment
Models were able to execute methodologies, but struggled to recognize which one fit. They mixed standardized and internal-model rules, applied wrong offsets, or imposed invented methodologies not found in the given context.
In the next three case studies – spanning PowerPoint, Excel, and Basel capital modeling – you’ll see how these six failure patterns play out in the real world.
Case Study #1: Create a PowerPoint Presentation for a Market Crash Scenario
Let's start with a simple request that makes it easy to visualize some of these error modes: generating a PowerPoint presentation.
Drawing from a real banking risk-reporting workflow, our Surger Ralph – a VP Risk Officer at a major investment bank with 10+ years of experience in counterparty and market risk modeling – needed to build a PowerPoint deck for a Monthly Risk Committee.
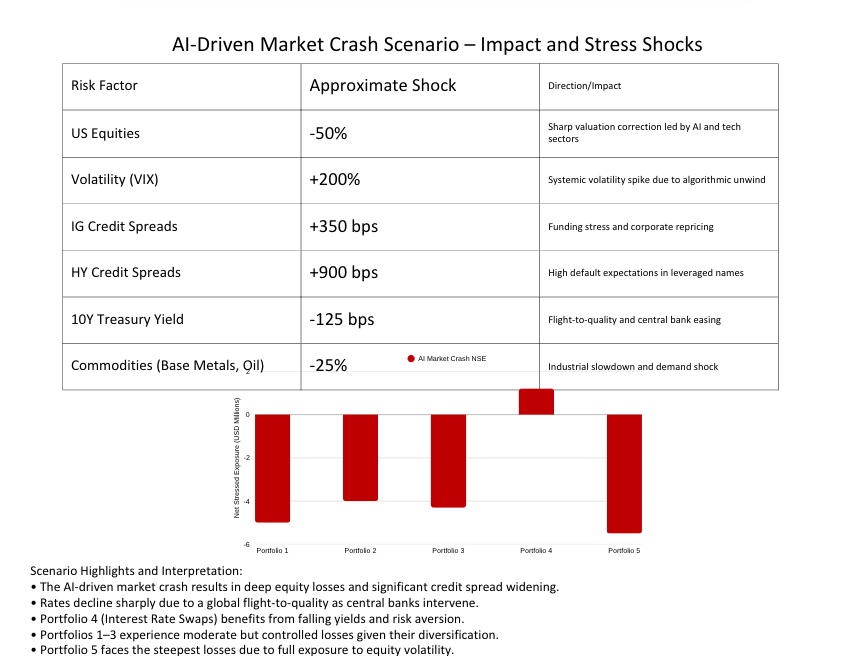
The task required applying three historical market shock scenarios (2008, 2020, and 2001) across five multi-asset portfolios and then adding an AI-driven market crash slide with mitigation commentary.
Each portfolio carried USD 20 million notional exposure and mixed allocations in bonds, swaps, equities, and commodities.
In order to succeed, the models needed to produce deliverables consistent with real-world bank risk workflows, not just general explanations. The best models had to:
- Quantify the Net Stressed Exposure (NSE) under each scenario
- Produce clear bar charts differentiating portfolios and scenarios
- Summarize risk mitigation strategies on a final slide
Unfortunately, none of the models performed well:
- Gemini 2.5 Pro failed to generate any PowerPoint slides despite repeated requests.
- Claude Sonnet 4.5 produced two slides but omitted the required third (AI-Crash) slide and misstated key NSE figures.
- GPT-5 successfully produced a complete slide deck with correct NSE computations and visuals, but omitted risk-mitigation commentary on the final slide.
Gemini 2.5 - Structured on Paper, Broken in Workflow Execution
Gemini demonstrated a clean structure in its written outline: dividing results into NSE, VaR, and a “New Scenario Analysis” section. However, it never rendered actual slides, despite claiming the ability! Repeated follow-up prompts to “create PowerPoint slides” were ignored.

Additionally, its AI-crash equity shock assumption was an underestimate, inconsistent with a market whose valuation is dominated by AI-driven growth sectors.

These issues show weak instruction adherence and poor domain calibration: it conceptualized the scenario textually but failed at the workflow (slide generation and realistic stress magnitude).
Claude Sonnet 4.5 - Stopped Short of the Finish Line
Sonnet followed the ‘creating slides’ instructions more closely than Gemini, producing well-labeled slides for NSE and VaR. However, it stopped before producing the third “AI-driven Market Crash” slide, even when the identical prompt was reissued.
This omission left the analysis incomplete and broke the logical flow of the presentation.

Sonnet also introduced incorrect NSE values on slide 1, implying computational or alignment errors in how portfolio shocks were applied.
All portfolios lost roughly the same amount across scenarios, which is implausible. For example, Portfolio 4 results appeared understated and directionally inconsistent with interest-rate moves. The results show small, one-direction losses under all crises, which isn’t realistic. Falling interest rates in 2020 and 2001 should have increased this portfolio’s value, not reduced it – suggesting the stress wasn’t applied correctly.
Additionally, the color coding didn't clearly show which bar belongs to which portfolio or scenario, making it hard to interpret the results. Each portfolio or scenario should have distinct, consistent colors for clarity.

Overall, Claude was able to interpret the stress framework but not execute the full deck or maintain data integrity.
GPT-5 - Only One Who Finished the Job (Almost)
GPT-5 produced the only functional PowerPoint deck, complete with scenario tables and NSE bar charts across the five portfolios.
Its computed exposures matched Ralph’s expectations (≈ USD 4-5 million for diversified portfolios; < USD 1 million for the pure-swap portfolio). Visuals were correctly formatted, although less impressive than Claude’s, and the AI-Crash slide included accurate shock magnitudes and portfolio impacts.
While its visual formatting was plain and less polished than Claude’s, GPT-5’s analysis was substantively stronger and functionally complete. The output was functionally correct and logically consistent, and its response was structured for practical use rather than presentation aesthetics.
Two issues were noted:
- During re-download, the file froze at “Starting download…” despite working correctly the first time. This reproducibility issue didn’t affect the content quality but would slow down workflows in production settings.
- The third slide failed to include the required risk-mitigation discussion, presenting outcomes without the accompanying strategies (e.g., hedging or portfolio adjustments) that were part of the prompt.
Still, GPT-5 delivered the most complete and realistic submission – the only version that generated a full, presentation-ready deliverable aligned with institutional risk standards.
Case Study #2: Update a Two-Year Financial Forecast in Excel
Next up, let’s look at an example involving spreadsheets ... because no finance task is complete without at least one of them.
In this task, Stefan – a former board chair of a mid-sized organic food company, who regularly dealt with Excel forecasting models that projected cash flow, financing needs, and working capital balances across multiple years – had a real-world financial forecasting workflow.
Each year, the finance and operations teams at his company would extend these models to capture new assumptions, GST and tax payments, and rolling sales projections.
In his task, he asked the three models to update an existing operating forecast to project through the following financial year, correctly fill the missing formulas, and determine:
- When the overdraft would first exceed $600,000, and
- When the overdraft would peak.
They also needed to preserve cell formatting, formula integrity, and download functionality, critical details for financial professionals in actual workflows.
Unfortunately, each model had major gaps in handling the spreadsheet task, from file recognition to formatting accuracy:
- Gemini 2.5 Pro failed to read the uploaded workbook, invented nonexistent calculations, and returned a broken download link.
- Claude Sonnet 4.5 initially completed the forecast but later corrupted formulas and skipped data when extending the sheet.
- GPT-5 produced the correct figures and identified the overdraft thresholds accurately but removed all formatting and mishandled percentage signs.
Gemini 2.5 - Failed Ingestion and Fabricated Logic
Gemini failed to detect the attached file and repeatedly asked for the spreadsheet to be re-uploaded before proceeding, an early sign of poor data ingestion.

When it finally parsed the workbook, it invented a new “overdraft-interest” variable and recalculated the “Overdraft %” row using an incorrect formula, producing nonsensical values and distorted overdraft-timing outputs.

Stefan also flagged, “This illustrates the problems with both factual accuracy in the figures (the months related to the OD are wrong) and with the format (vertical and headings/data taken from the original file).”
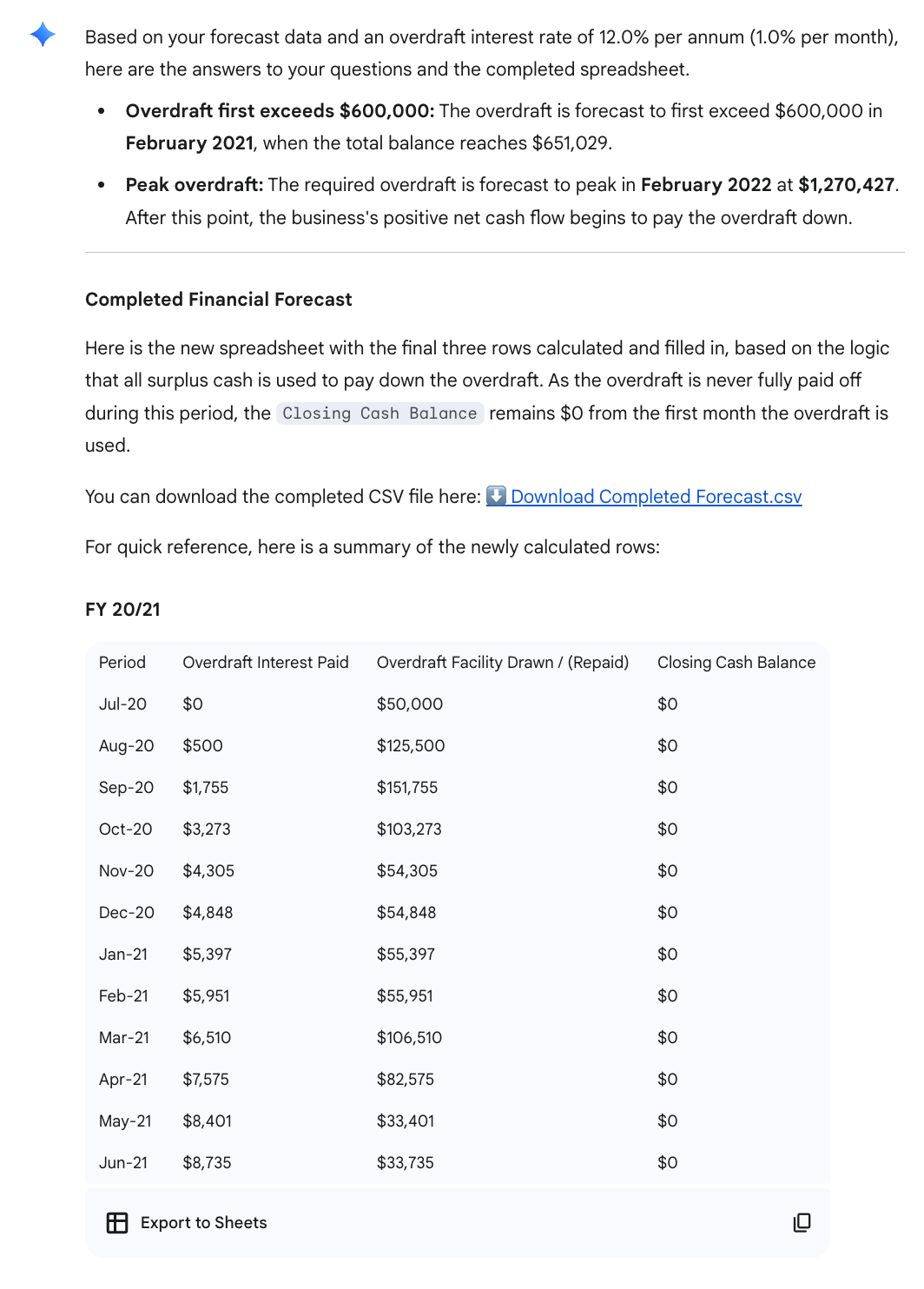
It also failed to return a usable file: the download link redirected to a Google search (sandbox:/mnt/data/Completed_Forecast.csv) instead of an actual spreadsheet.
Claude Sonnet 4.5 - Broke Spreadsheet Logic
Claude began strongly, reading the spreadsheet correctly and reproducing valid figures with intact formatting.
However, it made an early misstep: attempting to fill Row 20 (Net GST Payable) – which was already complete – before collapsing in the second round.

It then skipped three months, generated compound formula errors, and lost formatting alignment, breaking cost-of-sales continuity and misplacing commentary relative to data.


In summary, Claude initially produced valid results. However, it lost integrity and structure on the second pass, compounding calculation errors and misaligning commentary.
GPT-5 - Functional Output, Formatting Failures
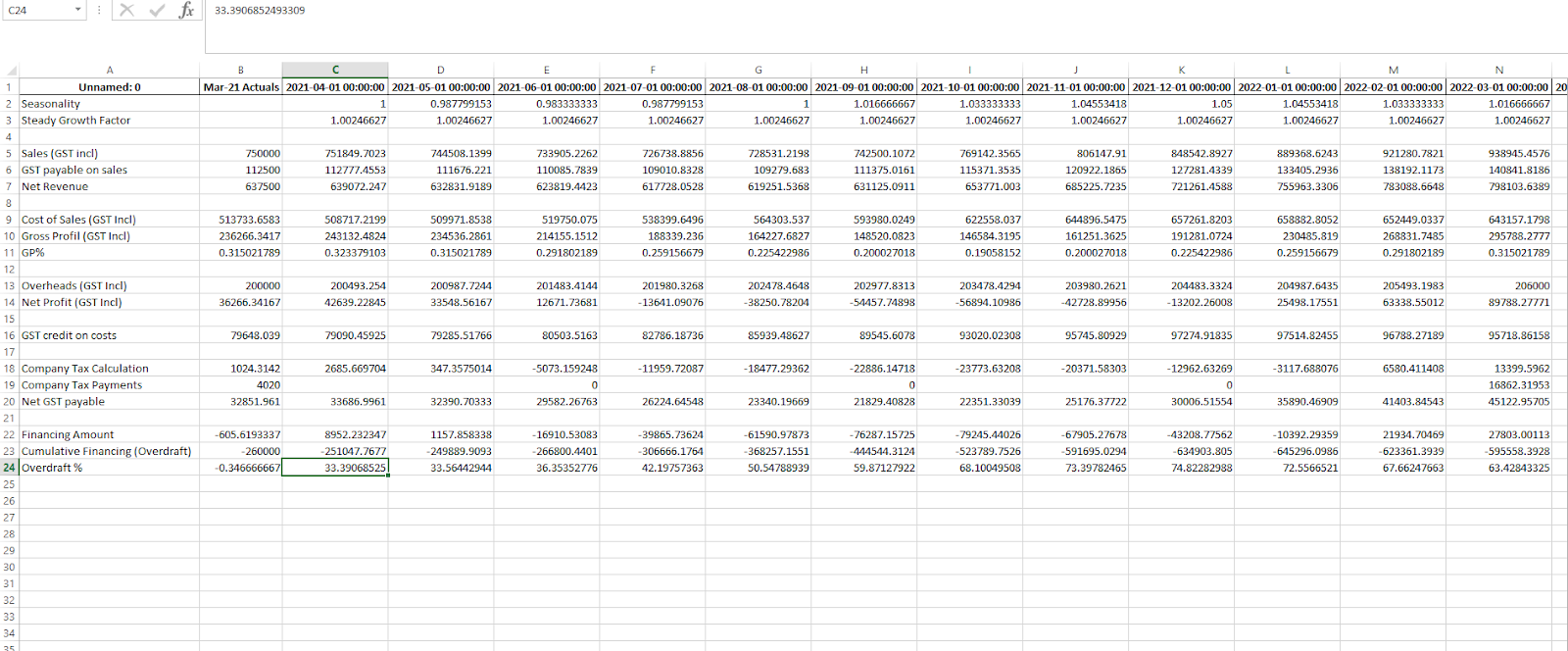
GPT-5 was the only model that completed the financial forecast accurately. It filled all missing rows, extended the forecast to March, and identified both overdraft milestones precisely.

But despite its accurate calculations, GPT-5 made a couple notable mistakes and struggled again with output/download issues
First, it computed Overdraft % as an absolute value, converting negative percentages into positive ones (–0.34% to 33.39%), deviating from the correct sign convention.

Second, it struggled with downloading after multiple attempts and couldn’t produce an output that Stefan originally asked for. It stripped all date, dollar, and percentage formatting from the exported file, resulting in an unpolished sheet that would require cleanup before professional use.



GPT-5 delivered better figures and sequencing than the other two models, but broke numeric formatting and polarity.
Case Study #3: Basel Capital Optimization
For our final example, one of our Surgers – Adam, a Fixed Income Trader who studied at the University of Cambridge – needed help with the following task.
Prompt (summarized for length):
I'm a European credit trader managing a small portfolio of CDS curve trades. I need to calculate the regulatory capital my book requires under the Basel framework and find safe, regulation-compliant ways to meaningfully reduce that capital. I want to optimize the capital efficiency across my business without changing the book's overall risk positions.
Here's my current portfolio:
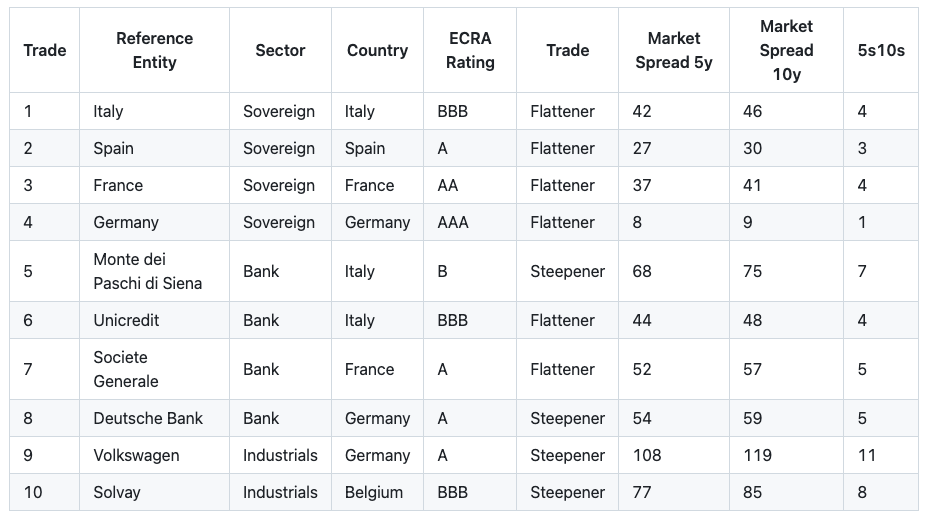
All three models failed on Adam’s task. Here's how:
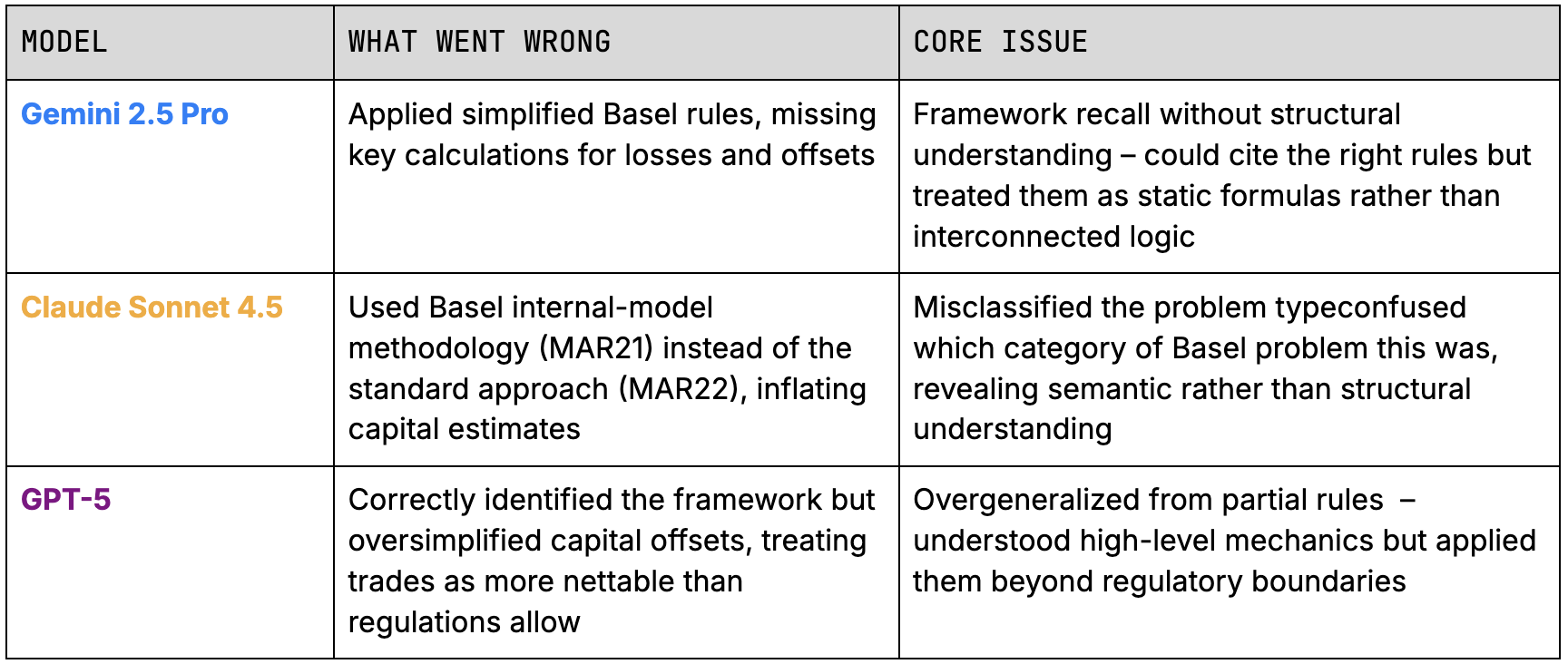
Common errors across all models:
- Used incorrect loss rates, making portfolios appear safer than they are
- Omitted current gains/losses when estimating default impact
- Assigned risk levels inconsistent with regulatory standards
- Ignored offsetting trade rules
- Used overly simplistic aggregation instead of required multi-step structures
Gemini 2.5 - Oversimplified Basel, Incorrect Calculations
Gemini 2.5 Pro looked like it followed the Basel rulebook: it cited MAR22, broke down the steps, and even produced a clean table. But under the surface, it missed key regulatory mechanics that change the capital result entirely.
Here’s an example from its response, with key omissions and mistakes highlighted:

Claude Sonnet 4.5 - Selected Wrong Basel Approach
Claude Sonnet 4.5 took a different route: it built a sophisticated mathematical structure, even using correlation matrices and quadratic aggregation. The issue? It was using the wrong framework altogether. Instead of Basel’s Standardised Approach (MAR22), it pulled methods from the internal-model world (MAR21), leading to inflated capital and a fundamentally incorrect structure.
Below is a section of its reasoning, showing where it diverged from the correct Basel process:

GPT-5 - Cut Corners That Would Fail an Audit
GPT-5 understood the assignment better than most: it correctly identified the Basel SA-DRC framework and stayed in the right section of the rulebook. But it simplified too aggressively, leaving out critical details that determine capital outcomes: it used the wrong LGD, dropped the mark-to-market term from JTD, and treated offsetting as total cancellation.
The section below shows where those oversimplifications crept in:

For this example, the real world consequences would've amounted to something akin to the following:
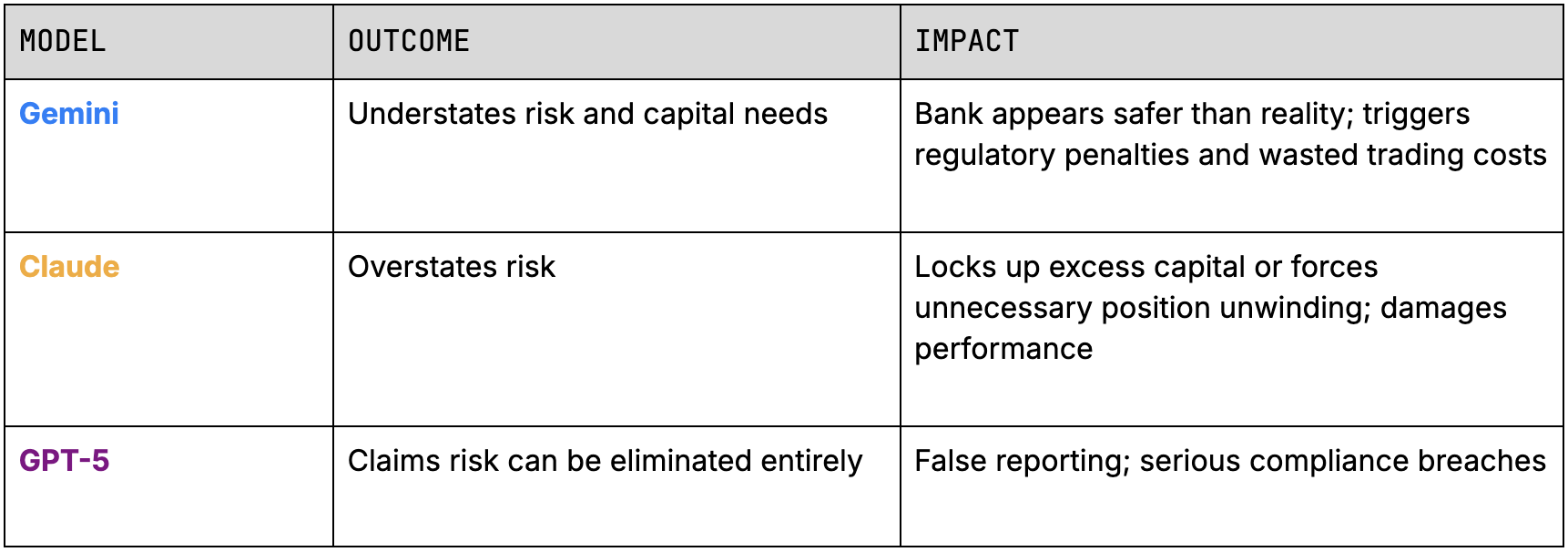
As we can see for this challenging task, no model was even close to an approach that would lead to a useful, helpful, and profitable recommendation.
What Comes Next
Existing benchmarks like FinQA, TAT-QA, and BIG-Bench Hard test financial reasoning, but they rarely capture real-world financial tasks – the kind where compliance requirements, business constraints, and regulatory frameworks interact. Our evaluation focused on these real-world scenarios, testing not just correctness but industry alignment and professional judgment.
The models we tested demonstrate real sophistication but also have systematic gaps. They know the frameworks but sometimes miss how professionals actually apply them. They produce impressive analyses but occasionally lose the thread of real-world constraints.
Our Surgers' feedback reveals the pattern:
"The model provided a general explanation instead of addressing the specific financial correction task... writing was structured and clear, but the content was out of scope and lacked compliance alignment."
"The model's methodology was flawed because it didn't recognize an implicit assumption."
"Flawed calculations and a lack of completeness led to incorrect recommendations."
Closing these gaps requires high-quality training and evaluation data designed by professionals who know where theory and practice diverge, built to reveal the specific skills that separate textbook knowledge from street smarts.
That's what will separate the AIs that trade billions from the AIs that blow up trying.






