
Imagine a world where AI helps us solve the Riemann hypothesis one day – producing not just the final answer, but also explanations of each mind-opening step. Could we teach it to do so? Just witness the magic already...

We recently created a dataset of 8,500 Grade School Math problems for OpenAI’s Reinforcement Learning team. The goal: to train language models like GPT-3 to solve natural language math problems and measure their reasoning ability.
Read the post by Karl Cobbe, Vineet Kosaraju, and John Schulman on OpenAI's blog! It’s also been adopted by many other research labs, including Google in their PaLM and Chain of Thought papers.

Dataset creation is a critical piece of AI, but it’s surprisingly underappreciated – ask most researchers, and they’ll have never inspected their datasets themselves! But how can you trust what you’re building when your inputs are junk? This is a real problem: for example, over 30% of Google’s GoEmotions dataset of Reddit comments is mislabeled…
At Surge AI, we care deeply about data, and we want everyone to share that same love. So we’re starting a “how we built it” series on dataset creation, starting with a deep dive into GSM8K.
How We Built It: Dataset Guidelines
First, what were the specifications behind the dataset? Here are the instructions that OpenAI created. A couple things to point out:
- The instructions are fairly short! While long, detailed instructions are sometimes necessary – particularly when there’s very nuanced, unintuitive criteria – one of the benefits of using high-quality labelers is that you don’t need to write 20 pages of guidelines outlining obvious points.
- Real-world examples are worth their weight in gold. We often see guidelines written by project managers who don’t understand the problems their product team is trying to solve; as a result, examples are nonexistent or armchair examples divorced from reality.
GSM8K Guidelines
Your goal in this project is to write simple grade school level math word problems and their corresponding solutions.
Criteria
- All problems should contain 2-8 steps in their solution.
- All calculations should be simple enough to do in your head without a calculator (e.g. 7*8, 36+110).
- The answer should be a single integer value. Any units should be specified as part of the question (e.g. "How much money, in dollars, does Robert have?"). Simple decimal numbers (e.g. 3.25) can be part of the intermediate steps in the problem, but final answers should always be integers.
- Writing "Jason has 8/2=4 apples" is preferable to writing "Jason has 4 apples", if you used the calculation 8/2 to determine how many apples Jason has.
- Only use elementary arithmetic operations: +,-,*,/.
- Don't reuse a problem setting. If you just wrote a problem about Samantha's trip to the zoo, don't write a second problem using that same premise.
Example #1
Question
Kendra has 3 more than twice as many berries as Sam. Sam has half as many berries as Martha. If Martha has 40 berries, how many berries does Kendra have?
Steps
Since Sam has half as many berries as Martha, he has 40/2 = 20 berries.
Since Kendra has 3 more than twice as many berries as Sam, she has 3+2*20 = 43 berries.
Answer
43
Example #2
Question
David has $300. He spent half of it on a new bike, and then he spent a third of what was left on a pair of sneakers. How much money did he have left?
Steps
David spent 300/2=150 on a new bike.
After buying the bike, David had 300-150=150 dollars left.
He spent 150/3=50 dollars on sneakers.
He had 150-50=100 dollars left.
Answer
100
Example #3
Question
Isaac has to buy some notebooks for the new school year. He buys 3 red notebooks and 2 yellow notebooks, for a total cost of $26. If the red notebooks cost $4 each, how much did the yellow notebooks cost each?
Steps
Let Y be the cost of the yellow notebooks.
3*4 + 2*Y = 26.
12 + 2*Y = 26.
2*Y = 14.
Y = 7
Answer
7
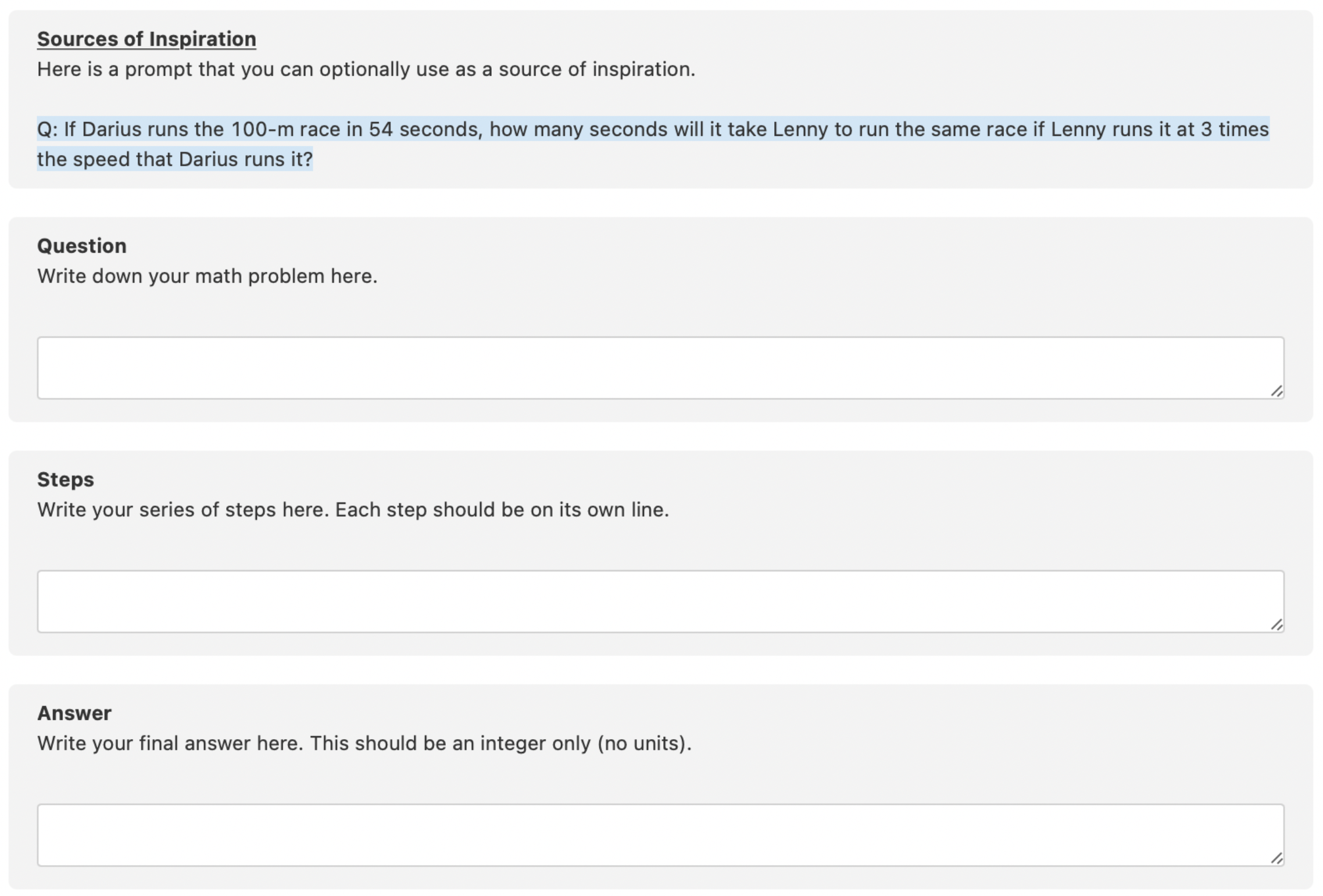
Data Labeling Interface
Here’s what the labeling task looked like in our UI.
Building a Mathematical Labeling Team
Our first step in creating the dataset was building a team of mathematically proficient Surgers. While this project doesn’t require advanced mathematical knowledge, we found it helpful to leverage Surgers with math or STEM degrees:
- They were less likely to make calculation errors. Even MIT Math PhDs inevitably make mistakes when solving middle school math problems, but having more experience makes it less likely.
- They were naturally speedier. Some people can quickly calculate 81 / 3 in their heads; others can’t.
- We wanted a diverse set of problems in order to capture the richness of mathematical reasoning, and experience helps.
Luckily, we do a lot of work creating advanced AI datasets – for example, creating datasets of Python programs to train coding assistants, or summarizing physics and chemistry papers – and so we already had hundreds of Surgers with technical degrees.
In order to further ensure that they could come up with well-designed math problems, everyone’s first 5 submissions were reviewed by another qualified Surger. Those whose problems passed were added to the team.
To give you a sense why this step is important, here were some of the problems created by Surgers who didn’t qualify into the team. (See if you can detect what’s off!)
Example #1
Question
After Bobby gets paid, Darren will have twice as much money as Bobby. Bobby currently has $40, and will be paid $16. How much money does Darren have?
Steps
Bobby will have $56 after he gets paid.
After Bobby gets paid, if Darren has twice as much money, Darren will have 2*56 dollars.
Darren currently has $112.
Answer
$112.
Example #2
Question
Mom has 10 oranges. Aunt Mary gave her 3 bags of oranges. Each bag has 2 oranges in it. How many oranges does Mom have now?
Steps
3*2=6
10+6=16
Answer
16
Mathematical Surgers
So who are the folks in the GSM8K team? Here are some of the Surgers in their own words:
Joe
I have a degree in Mechanical Engineering, but I spent about 25 years developing internet software. I've worked in a variety of roles from sales to development, written two books about software development and I'm now semi-retired. Despite the fact that I have loads of hobbies, I feel the need to continue to do at least some work. If it weren’t for Surge, I’d probably drive for Uber, for both the conversation and extra pay.
Maria
My bachelor’s degree was originally in Physics, 20 years ago, but I quickly decided I was more interested in Biochemistry instead, and I went on to do my PhD and a postdoc. I met my husband in grad school, and we had a son a few years later.
I found working as a scientist whilst raising my child challenging, and embraced the opportunity to become a full-time stay-at-home mom for a while. I worked part-time jobs as my son grew up, including painting, insurance, and sales. Eventually I landed up on Surge, where I appreciate being able to make money from home during a pandemic.
Looking back, I am quite nostalgic over the old days when I worked as part of a team doing cutting-edge research. Nowadays, I get that team feeling from the forums, where we all take the time to help each other. And from being a part of academic studies, albeit from the other side!
Data Labeling Efficiencies
To improve Surger efficiency, the OpenAI team also provided a list of auto-generated “starter problems” that were useful for inspiration.
For example, here were some of the auto-generated problems:
Q: The average number of people attending movies on Saturday was twice the average on Friday and three times the average on Sunday. Bulliver went to a movie on Friday, Saturday, and Sunday. What was the average number of people at the movies that he went to?
Q: John's favorite number is the square root of George's least favorite number. What is John's favorite number?
However, because the problems often didn’t make sense and had to be substantially reworked, most Surgers found it easier to create problems from scratch.
Ensuring Problem Diversity
One crucial part of this project was ensuring that Surgers created a diverse set of problem scenarios.
For example, we didn’t want people to create two problems like this:
Sam buys 5 apples and 2 oranges at the supermarket. If apples cost $1.00 each and oranges cost $3.00 each, how much does he spend on groceries?
Jason buys 3 apples and 4 bananas at the grocery store. Apples cost $2.50 each and bananas cost $0.25 each. How much does he spend?
While we told Surgers to generate each problem scenario from scratch, sometimes problems would accidentally end up too similar.
In order to prevent this issue, we calculated a sentence embedding for each problem statement, calculated the cosine similarity between all pairs of problems (the OpenAI team also provided their own similarity measures), and threw out all problems above a similarity threshold.
For example, here's one of the problem pairs that we discarded:
Pair
Seven bottles of soda cost $21.00 while 4 bottles of water cost $8. If David wants to buy 3 bottles of soda and 2 bottles of water, how much will that cost?
Five pens cost $7.50 while 4 pencils cost $1. If Andrew wants to buy 3 pens and 2 pencils, how much will that cost?
Ensuring Mathematical Correctness
Another crucial part of the project was ensuring that all problems had mathematically correct answers.
As a first pass, we asked Surgers to double-check their work for mistakes.
However, we also realized that some of the math problems were ambiguous: there could be several natural interpretations of the problem that would lead to different answers.
For example, here is a subtly ambiguous problem:
When Nathan is cold, he adds an extra blanket to his bed. Each blanket warms him up by 3 degrees. One night, he was cold enough that he added half of the 14 blankets in his closet onto his bed. How many degrees did Nathan’s blankets warm him up?
The ambiguity: is there a blanket already on Nathan’s bed, leading to 8 blankets? Or does he end up with only 7 blankets total?
Even if you read the problem carefully, you may think one interpretation is so obvious you don’t realize someone else may disagree. As a result, in order to catch these ambiguities, we asked two Surgers to solve each problem, paying extra attention to the language, and double-checked any problems where at least one of their answers differed from the original.
Research
Now marvel at GPT-3’s mathematical reasoning!

If you’re interested in diving more into the research that makes use of this Grade School Math dataset:
- Training Verifiers to Solve Math Word Problems is the original paper by OpenAI that introduces the dataset.
- This Github repository contains a downloadable version of the dataset.
- Google uses the GSM8K dataset in their PaLM (540B language model) and Chain of Thought papers.
What’s more, AI models are already learning to solve IMO problems… Will P vs. NP be next?

QED. Thanks Karl Cobbe, Vineet Kosaraju, John Schulman, and the entire OpenAI team for the collaboration!






