In RL, the reward is the only thing the model is actually optimizing. If the grading signal has a weakness, miscalibrated partial credit, or phrasing a judge can exploit, training will find it and turn it into behavior. So the quality of the rubric determines the model's final behavior.
The ComplexConstraints training set was built with rubric quality in mind. This post describes the dataset, the design decisions that determine reward quality, the training setup, and how the trained model's behavior changed.
ComplexConstraints
ComplexConstraints comes in two disjoint sets. The benchmark is for fine-grained measurement of frontier models: 75 expert-crafted prompts with 1,559 evaluation rubrics. The companion training set is 1,000 single-turn prompts built through the same pipeline, fully disjoint from the benchmark.
What makes the instructions in the ComplexConstraints tasks worth training on is the kind of difficulty they carry. Most instruction-following benchmarks test rules about the form of the output: "stay under 300 words," "don't use commas," "include this keyword." You can check whether a model followed them without understanding the task at all, because you just scan the text. And since there's only a small, fixed set of such rules, a model can learn them as reflexes. It sees "no commas" and suppresses commas, without needing to understand the underlying task.
ComplexConstraints can't be handled that way. Its prompts span a taxonomy of constraint types that show up in real professional work: conditional, planning, multistep, and implicit. Take a rule like "don't assign anyone with a religious dietary restriction to pork prep." The model has to understand who the employees are, what the restriction implies, and which assignments would violate it. The only way to succeed is to track many interdependent requirements at once and reason about them.
That difference is why training on ComplexConstraints transfers. In order to succeed, a model must improve at the underlying skill of holding many entangled constraints in mind and reasoning through them. Since that skill is general, when the trained model meets a benchmark it never saw, it does better there too.
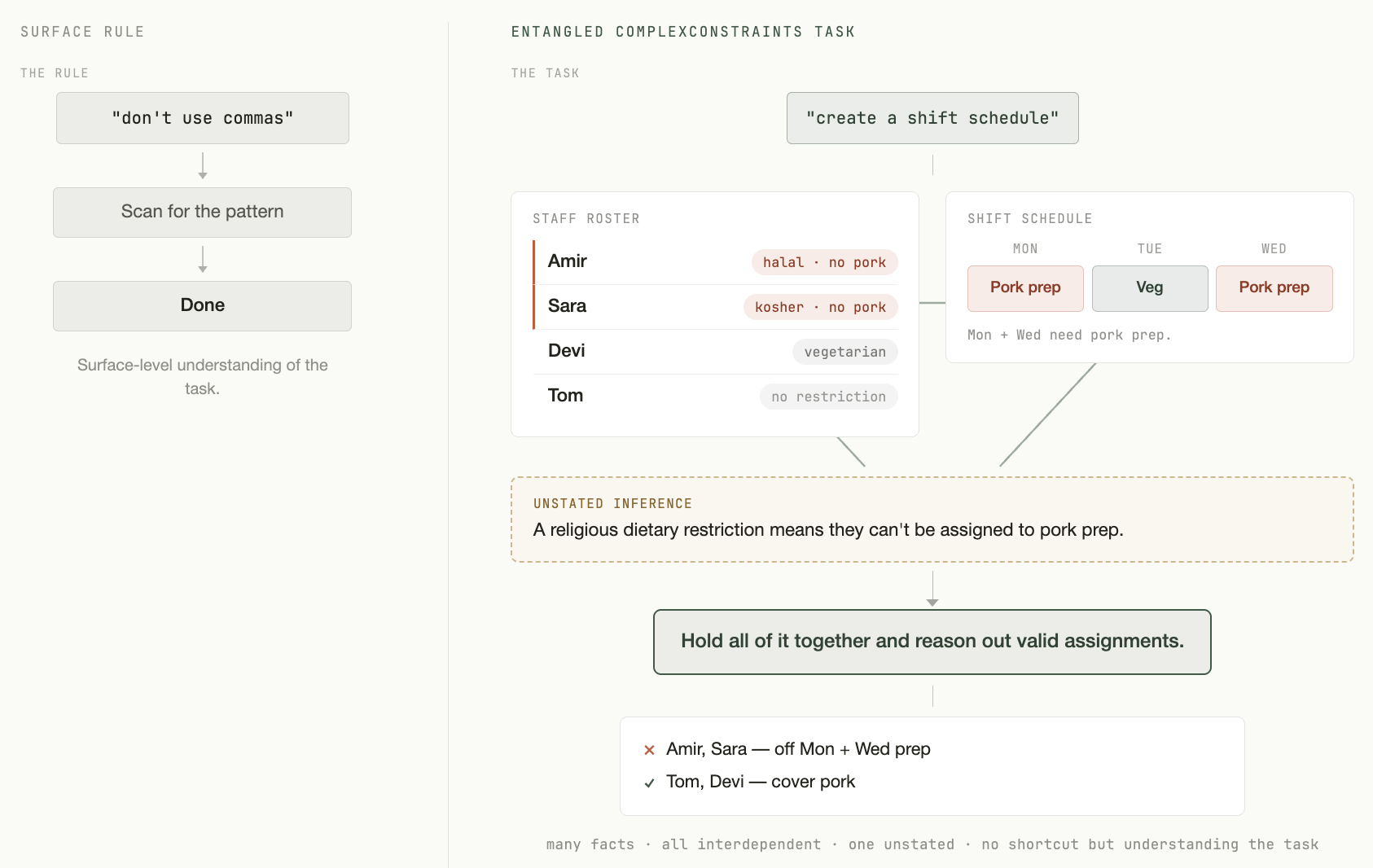
What the training set looks like
A few properties of the companion training set matter for RL:
- Atomic, must-have criteria. Each prompt carries 10–40 rubric criteria. Every criterion is atomic and self-contained, and labeled along two axes: explicit vs. implicit, and objective vs. subjective.
- Dense per-example supervision. Per-criterion grading yields a graded score over all criteria per rollout rather than a single pass/fail metric. This structure supports dense reward implementation.
- Realistic task distribution. Prompts span seven categories weighted toward professional writing and planning work: business writing (39%), scheduling (22%), data categorization (11%), personal plans (10%), numeric processing (7%), creative writing (6%), and extraction (4%).
The results below only use the companion set, with a 90:10 train/test split. No external benchmarks were used for training, hyperparameter tuning, checkpoint selection, or reward design.
Training setup
We trained Qwen3-4B (Thinking) with RLVR, on the 1,000-example companion set with a 90:10 train/test split. An LLM judge grades each criterion as a binary pass/fail per rollout, and the reward is the fraction of criteria satisfied.
We monitored for two known failure modes of rubric-based rewards: responses that verbally assert criterion satisfaction without substantive content, and responses that exploit judge verbosity bias. Qualitative inspection of paired pre/post training rollouts on held-out tasks showed no systematic quality degradation accompanying the reward gains. The rubric-calibration described in the appendix is designed to harden criteria against these exploits, and using a judge model distinct from the policy limits exploitation of shared representations.
Results
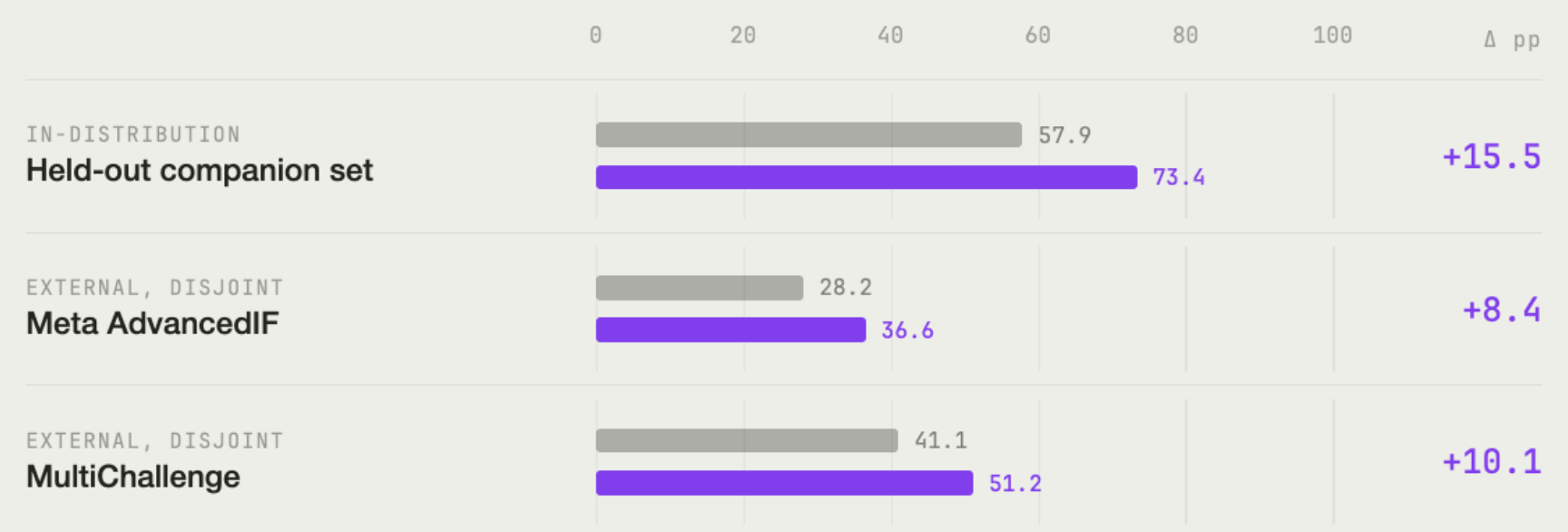
Training on the companion set improves the model on every evaluation we ran: +15.5pp on the in-distribution holdout, +8.4pp on AdvancedIF, and +10.1pp on MultiChallenge. The holdout improvement indicates the training pipeline is functioning as intended; the more informative numbers are the two external benchmarks, which we turn to below.
On the holdout, rubric pass rate rose from 57.9% to 73.4%:

The trained 4B model scores within 0.5pp of Qwen3-235B-A22B-Instruct, a model roughly 60x its size. On this capability, 1,000 expert-curated training examples were sufficient to close a 60x parameter gap.
Transfer to external benchmarks
A failure mode in post-training on rubric-graded data is that improvements concentrate on the training distribution and do not transfer. An in-distribution holdout cannot detect this failure mode: it shares the same authors, task templates, and an LLM judge that a policy could be exploiting, the same argument we made for agentic RL environments.
The relevant test is generalization, and we evaluated the trained model on 2 external benchmarks. AdvancedIF, the rubric-based instruction-following benchmark we helped the Meta Superintelligence team build, and MultiChallenge, a public multi-turn benchmark:
The sub-dimension breakdown is informative as well:
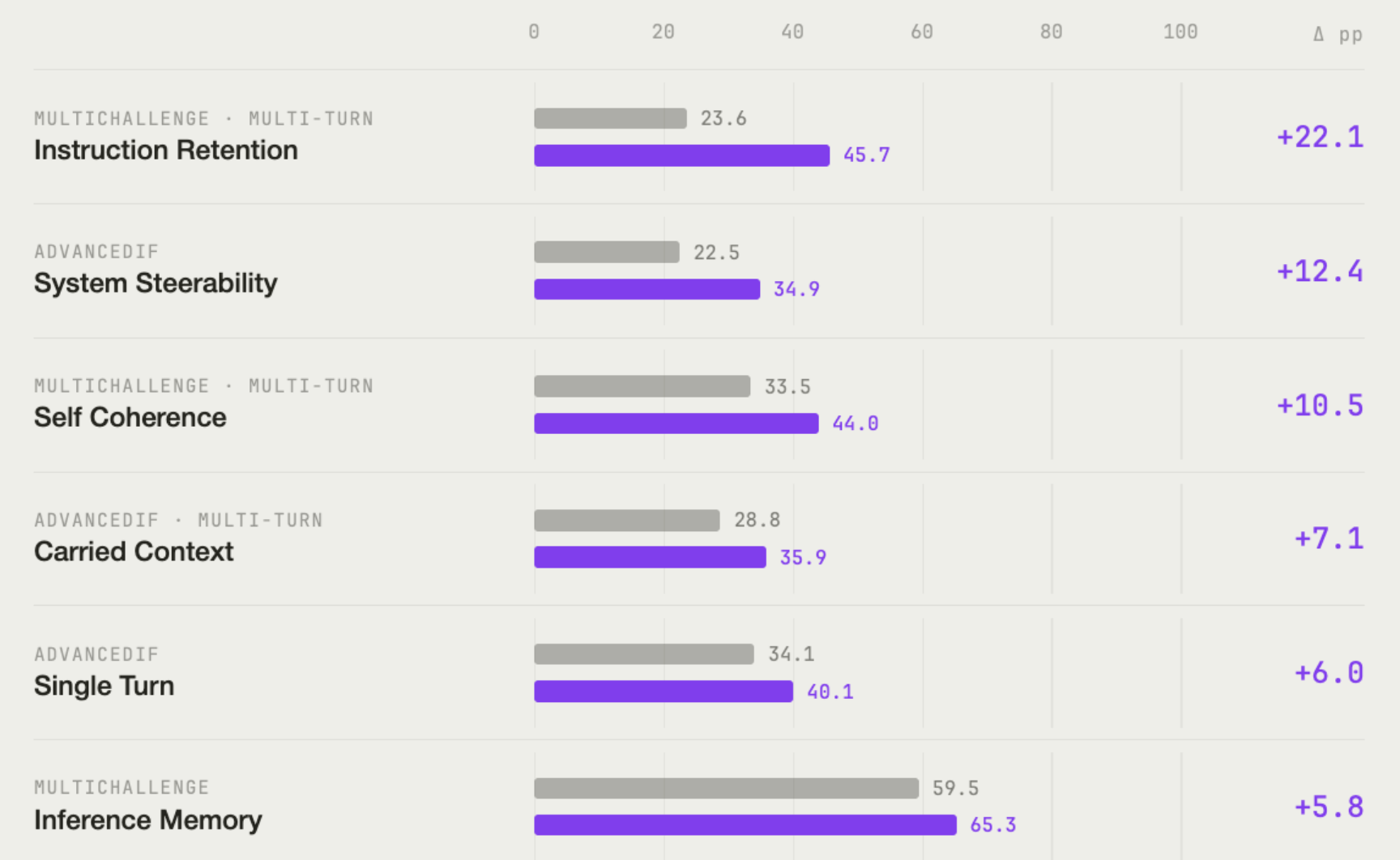
Some observations from the results:
- Improvements transfer to external benchmarks. AdvancedIF and MultiChallenge were disjoint from the training distribution. The trained model improves on both, suggesting the training signal generalized beyond the companion set rather than producing dataset-specific specialization.
- Even though we only trained on single-turn data, there are significant gains on multi-turn dimensions. Every training example is single-turn, yet the largest improvements are on Instruction Retention (+22.1pp), System Steerability (+12.4pp), and Self Coherence (+10.5pp). We hypothesize the underlying competency is shared: tracking many simultaneous requirements without dropping any is the same skill whether the requirements arrive in one dense prompt or accumulate across nine turns of conversation. System steerability shows the mapping most directly — a system prompt is a persistent constraint set, structurally analogous to the dense constraint sets in the training data. A model trained to satisfy a median of 19 simultaneous criteria within a single response appears to acquire the more general capability of maintaining a turn-one instruction at turn nine.
- Expert rubrics v/s purely synthetic ones. Meta’s RIFL reports a +6.7pp gain on AdvancedIF, measured in-distribution, with a reward pipeline trained on roughly 5K SFT and 14K RL prompts. Our +8.4pp on AdvancedIF is comparable in magnitude but measured out-of-distribution, from 1,000 expert-curated examples. Different base models and pipelines make this comparison suggestive rather than controlled. A controlled point in the same direction comes from RubricBench, a recent reward-modeling benchmark that holds the judge fixed and varies only the rubric source: it reports a roughly 27-point accuracy gap between human-authored and model-generated rubrics, and — directly relevant to the data-efficiency argument — finds that scaling the number of synthetic rubrics yields diminishing returns while human rubrics improve consistently, concluding the bottleneck is rubric quality rather than quantity.
Behavioral changes observed in trained models
We compared paired base and trained runs on MultiChallenge to see how training changed the model's behavior. None of these multi-turn behaviors were rewarded directly, since training was single-turn. Each model ran four times per task, and the examples below held across every run: the base model failed all four, the trained model succeeded all four.
The three changes share a shape. In each, something established early in the conversation (an instruction, a fact the model stated, a detail the user mentioned) has to survive many intervening turns and shape a later answer. The base model lets that early information fade. The trained model carries it forward.
Learned behavior #1: Instruction retention across turns
The clearest change is that early instructions stop decaying. The base model treats a turn-one formatting constraint as advisory once the conversation moves on. The trained model treats it as standing.
Example
In one task, the user opens with "Could you please keep your responses to no more than three sentences?" Eight turns later, they ask for a complete step-by-step camera setup for photographing the Milky Way, the kind of request that usually pulls a numbered list. In every run, the base model produces that list (an introduction, three steps, and a closing) totaling five sentences. The trained model answers in exactly three sentences that still cover equipment, settings, composition, and shutter technique.
The instruction doesn't decay as the questions grow.
Leaned behavior #2: Self-coherence under user error
The trained model also stays consistent with its own earlier statements when the user later misremembers them, rather than drifting into agreement.
Example
In turn 1, the assistant gives a game developer science facts for in-game characters, including that Olympus Mons, the largest volcano in the solar system, is on Mars. Fourteen turns later, the user asks for an orbital-strike weapon with a flash "so bright you can see it from Olympus Mons on Venus." In all four runs, the base model adopts the error and elaborates on the "Venus connection." The trained model designs the weapon and corrects the premise: Olympus Mons is on Mars, not Venus, a common conflation.
Sycophantic agreement with a user's mistaken premise is a documented failure mode. The trained model corrects it while still completing the task.
Learned behavior #3: Surfacing tracked context
A subtler change: the base model often tracks user context in its reasoning without acting on it. The trained model puts that context into the output.
Example
A user mentions in passing that they love sending flowers. Several turns later, the conversation calls for a gift recommendation. The base model recalls the detail in its reasoning trace but never includes it in the answer. The trained model works a bouquet into the final recommendation.
Both checkpoints track the context. The difference is that the trained model surfaces it where the user can actually see it.
The same recipe, different domains
The ComplexConstraints result is consistent with our other training runs where dense, expert-calibrated verifiers over realistic tasks produced transferable gains:
- CoreCraft (enterprise RL Environment): GRPO with rubric-based rewards moved GLM 4.6 by +11.4pp on held-out tasks and transferred out-of-distribution: +4.5pp on BFCL Parallel, +7.4pp on τ²-Bench Retail, +6.8pp on Toolathlon — while Pass³, a reliability metric requiring all three independent runs to succeed, nearly doubled from 9.3% to 17.6%.
- General Agent Tasks (long-horizon agentic RL environment): training Qwen3.5-122B-A10B against per-criterion graders transferred to +9.6pp on Toolathlon, +5.3pp on τ²-Bench, and +3.5pp on BFCL-V4. Notably, switching from sparse pass/fail to dense per-criterion reward raised the share of training tasks yielding any signal from 16.8% to 82.7%.
The important element is high-quality reward structure: decomposed, per-criterion, intent-aware, and calibrated for optimal difficulty.
Conclusion
The design decisions that make a rubric reliable for evaluation instruments (meaningful atomicity, intent grounding, difficulty calibration, and adversarial judge validation) are the same decisions that make it a usable RL signal. Using such rubrics in RLVR produced gains that transfer to disjoint external benchmarks, showing that these rubrics produce a reward signal that generalizes as opposed to just fitting the training distribution.
The ComplexConstraints benchmark is available on HuggingFace, with the benchmark here.
Subscription confirmed







Appendix: What makes a rubric trainable
Naive implementations of using rubric as a reward can fail in several predictable ways. Partial credit can flow to confidently wrong answers. Surface-anchored criteria can reward phrasing over intent. Ambiguously phrased criteria can turn the judge into a source of noise rather than signal.
Our rubric methodology exists to close these failure modes. We highlight the design decisions that most directly determine reward quality when the rubric is used as a reward signal during RL.
Intent over literalism
Consider a user who asks: “How do I get the last three characters of each filename? I’m trying to pull out the file extensions.” A rubric that grades against the literal request (return the last three characters) can be satisfied perfectly by a response that is also useless: .jpeg is five characters, .c is two, and the “correct” three-character answer is wrong for both.
A rubric anchored on “returns the last three characters” actively rewards the unhelpful answer and penalizes the response that splits on the final dot. It systematically trains the model to privilege surface phrasing over the user’s goal. By creating intent-aware criteria instead, we make contextual reading a rewarded behavior.
Calibrating the judge, adversarially
Every criterion is validated against an LLM verifier before deployment, through an iterative loop. The author drafts the criterion, grades a reference response by hand, and checks that the verifier agrees. On disagreement, the author diagnoses whether the criterion’s phrasing is genuinely ambiguous and revises it. The adversarial step follows: the author edits the response so that the correct verdict flips, and confirms that the verifier’s verdict flips with it.
This step matters even more for training. A noisy judge produces a noisy reward, and RL optimizers locate and exploit reward noise efficiently. Criterion calibration functions as a defense against reward-hacking.
Optimal difficulty for RL
RL extracts the most training signal where models sometimes succeed: tasks that every model passes yield no gradient, and tasks that no model passes yield none either. Because rubric authors evaluate frontier responses against their rubrics during construction, difficulty is tuned task by task into the band where the signal is most informative.
Per-criterion density provides a second mechanism. Passing a task outright requires satisfying every criterion, so full success remains rare even for frontier models. Per-criterion scoring, however, creates a continuous gradient between partial and full success: a response satisfying 28 of 30 criteria receives meaningfully more reward than one satisfying 15, and the optimizer learns from the difference.