Why transfer is the right thing to measure
A failure mode in post-training on RL environments is that improvements can concentrate on the training distribution and not transfer. A policy optimized against a fixed environment can exploit any consistent feature of its reward landscape, including features specific to that environment's tool surface, grader implementation, or task templates, producing capability gains that reflect specialization to the training environment rather than improvement in the underlying skills it tests. The held-out split of the training distribution does not detect this failure mode: an in-distribution holdout shares the same environmental features the policy is exploiting, so a model that has overfit to the environment can continue to score well on it.
The relevant test is on external benchmarks, and the gap between in-distribution improvement and external-benchmark improvement is informative about how much of the observed gain reflects genuine capability rather than specialization to the training environment.
We designed our evaluation accordingly. The holdout serves as an in-distribution check on the training pipeline. Transfer is evaluated on three external public benchmarks: Toolathlon, τ²-Bench, and BFCL-V4. These were chosen to cover a range of agentic capabilities, including multi-server tool use, long-horizon planning, and function-calling correctness, and are disjoint from the training set. None of these benchmarks were used for hyperparameter tuning, checkpoint selection, or reward design.
The training environment
Long-Horizon Multi-Tool Agent Tasks is one of our long-horizon agentic RL environment collections: a suite of tasks across 27 categories, covering surfaces commonly used in productive work, including spreadsheets and document editing, terminal and bash, calendar and scheduling, search, and file systems. Each environment is exposed as one or more MCP servers, and each task includes a deterministic Python grader that scores task completion from final state. All tasks are verifiable, and the per-criterion structure of the graders supports both sparse (binary pass/fail) and dense (partial-completion) reward designs.
Several properties of this environment are relevant for RL training:
- Long-horizon. Tasks generally require 25-40+ tool-calling turns and 80K-100K tokens to complete. The benchmark targets planning and context management rather than single-shot tool use.
- Multi-tool, multi-API. Individual trajectories regularly span multiple MCP servers: for example, a Playwright browser, an Excel reader, a file system, and a calendar API combined within a single rollout.
- Per-criterion graders. Graders evaluate task completion piecewise (e.g., 8 of 10 criteria satisfied). This structure facilitates dense reward implementation if needed, and increases the proportion of training tasks that yield usable reward signals.
Training setup
We trained Qwen3.5-122B-A10B with LoRA (rank 32, alpha 32, applied across attention and MLP projections). The pipeline consists of two stages: an SFT stage, followed by RL with GSPO as the advantage estimator. Training infrastructure was built on top of slime, Megatron-Bridge, and SGLang.
We highlight some design decisions that materially affected training outcomes:
1. SFT before RL, to address reward sparsity
Initial experiments established that the base model was not strong enough to begin RL training directly: the majority of tasks were too difficult for the base policy even with multiple attempts (pass@k), and the resulting reward sparsity prevented productive RL training.
We added an SFT stage to expand the surface area of solvable tasks, providing sufficient reward signal for the subsequent RL stage. The SFT+RL pipeline could be a useful recipe when baseline pass rates are too low to derive useful reward signals from RL alone; stronger base models will likely benefit less from the SFT stage.
2. Dense reward derived from per-criterion graders
Our initial training runs used sparse, binary pass/fail rewards. The result was substantial reward sparsity: on Qwen3.5-122B-A10B, only 16.8% of training tasks produced any reward at pass@4. On Qwen3.5-35B-A3B, the corresponding figure was 2.4%.
Because our graders score tasks per-criterion, we implemented dense reward as a drop-in modification. Each trajectory receives a reward equal to the fraction of grader criteria satisfied.
Switching to dense reward produced a substantial increase in usable training signal. For Qwen3.5-122B-A10B, the average per-task reward increased from 0.30 (sparse) to 0.51 (dense), and the share of training tasks producing any reward increased from 16.8% to 82.7%. With dense reward in place, RL produced steady improvements in raw reward across training steps.
Results
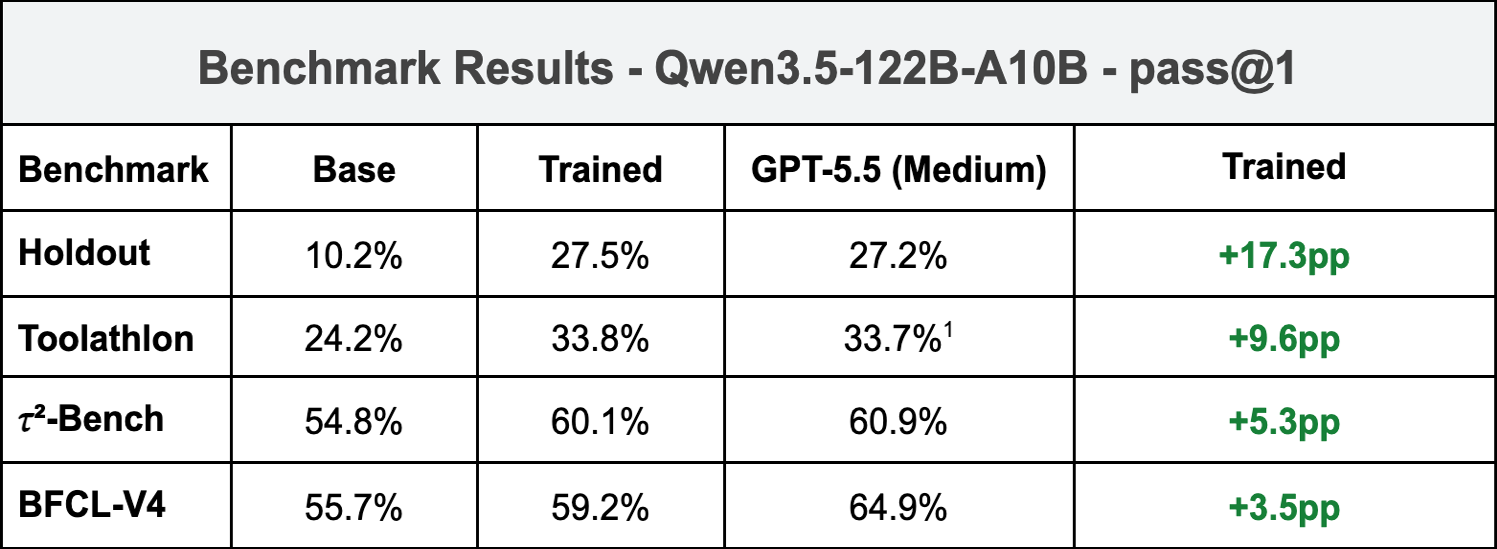
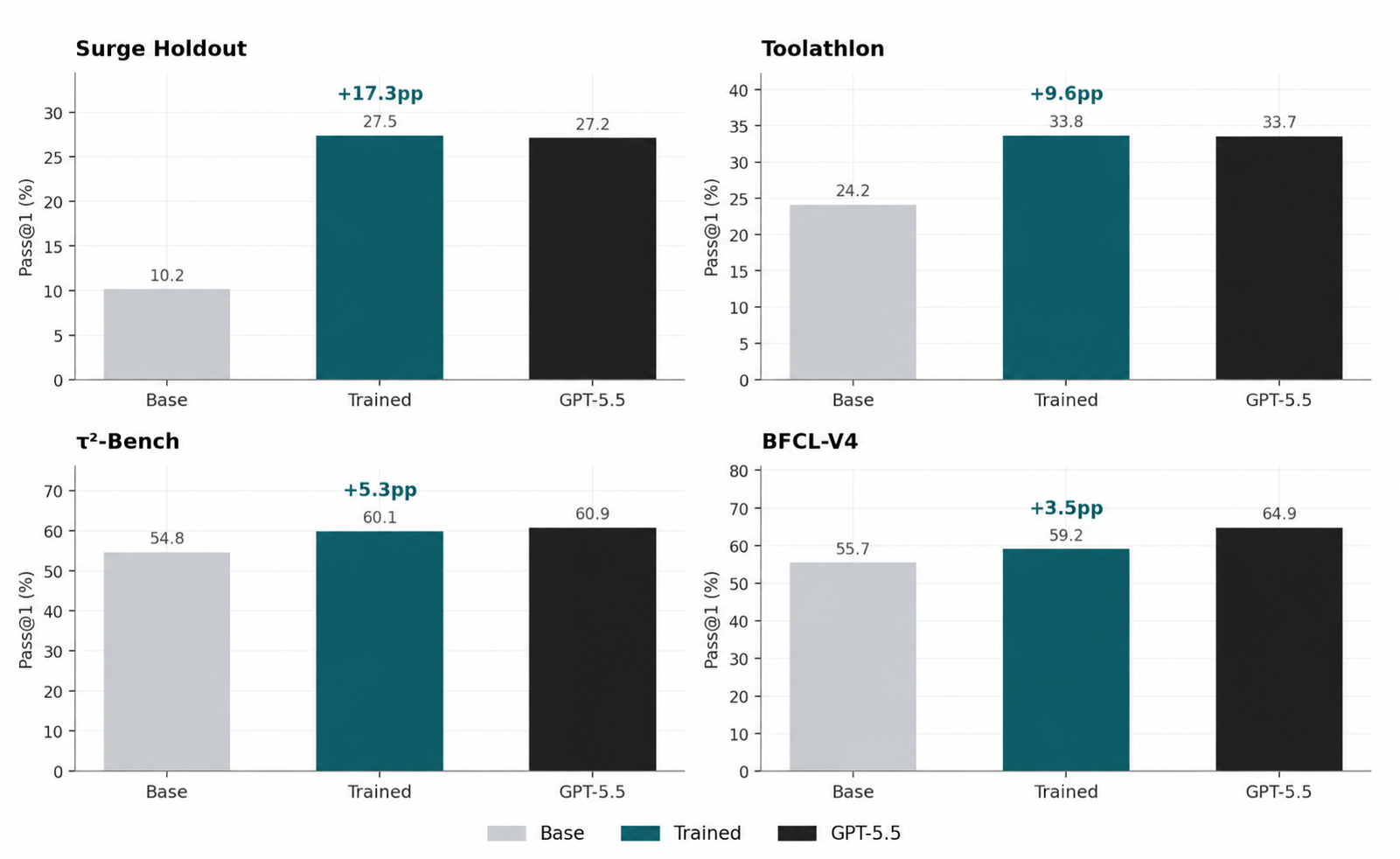
Training on our Long-Horizon Multi-Tool Agent RL environments improves the SFT+RL model over the base on every benchmark we evaluated. At pass@1, the model gains +17.3pp on the in-distribution holdout, +9.6pp on Toolathlon, +5.3pp on τ²-Bench, and +3.5pp on BFCL-V4. The holdout improvement indicates the training pipeline is functioning as intended; the more informative numbers are the gains on the three external benchmarks (Toolathlon, τ²-Bench, BFCL-V4), none of which were used during training in any form. On three of four evaluations at pass@1 (Holdout, Toolathlon, and τ²-Bench), the trained model performs within approximately 1pp of GPT-5.5 at medium reasoning effort.
We evaluated the base model and three training conditions (SFT only, RL only, and SFT+RL) on the in-distribution holdout and the three external benchmarks, at both pass@1 and pass@4. All Qwen3.5-122B-A10B evaluations were run with full precision (BF16) using H200s and SGLang. GPT-5.5 was evaluated using Azure AI Foundry at medium reasoning effort.


Some observations from the results:
- Improvements transfer to external benchmarks. Toolathlon, τ²-Bench, and BFCL-V4 are all disjoint from the training distribution. The trained model shows measurable improvements on all three, suggesting that the training signal generalized beyond the Long-Horizon Multi-Tool Agent Tasks used for training rather than producing environment-specific specialization. The +17.3pp improvement on the in-distribution holdout indicates the training pipeline was functioning as intended.
- The trained model performs comparably to GPT-5.5 (medium) on two of three external benchmarks. On Toolathlon and τ²-Bench, the trained model is within approximately 1pp of GPT-5.5 at medium reasoning effort, at pass@1.
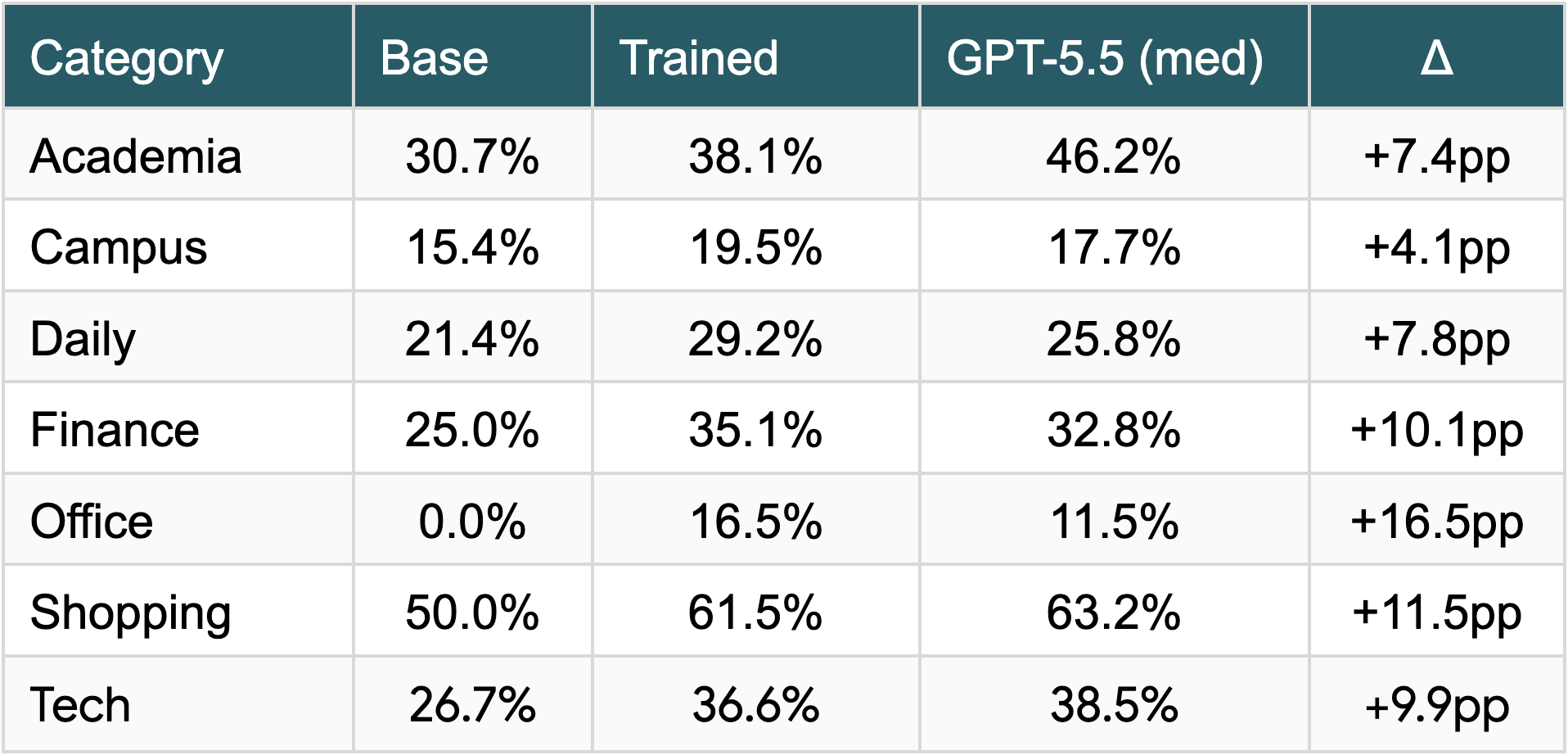
Toolathlon performance deep dive
Performance on Toolathlon varies substantially across categories. The largest single-category improvement is Office (0.0% → 16.5% at pass@1): the base model completed essentially no Office tasks, while the SFT+RL model resolves 16.5%. Finance (+10.1pp), Shopping (+11.5pp), and Tech (+9.9pp) also show substantial improvement. GPT-5.5 outperforms the SFT+RL model on Office at pass@4 by a wide margin; we hypothesize this reflects a corpus advantage on office-related tasks (GPT-5.5's Office performance increases over 200% from pass@1 to pass@4, while the SFT+RL model's increase is more modest). At pass@1, the SFT+RL model exceeds GPT-5.5 on Campus, Daily, Finance and Office tasks.

Behavioral changes observed in trained models
Trajectory analysis of base, SFT-only, and SFT+RL checkpoints surfaced consistent behavioral changes that emerged from training. None of these were explicitly rewarded by the reward function.
Parallel tool invocation
After RL training, the model began issuing multiple tool calls in a single turn when the calls were independent. For example, the model would read multiple memory keys simultaneously rather than query them sequentially. Beyond improving turn efficiency, this behavior reduces context-window-exhaustion failures on long-horizon tasks that require consolidating evidence across many lookups. The behavior was not present in the base or SFT-only checkpoints in our trajectory comparisons.
Task closure
Another change is improved task closure. The base and SFT-only models frequently failed on multi-step Office-style tasks by entering exploratory loops (reading files, parsing spreadsheets, drafting intermediate processing scripts) without executing the final write step or producing the required output artifact. The SFT+RL model completes these workflows end-to-end.
Example: the Library Catalogue Update task (drawn from the holdout) requires the agent to read four reports (delivery, damage, donations, shelf purges), cross-check against an existing catalogue, and write a sorted ADD/DELETE list to /workspace/updates.txt. Both the base and SFT-only models gather correct supporting evidence but fail to produce the output file. The SFT+RL model recovers from an initial incorrect sheet assumption, parses the catalogue, cross-checks against existing entries, writes the output file, and verifies its contents.
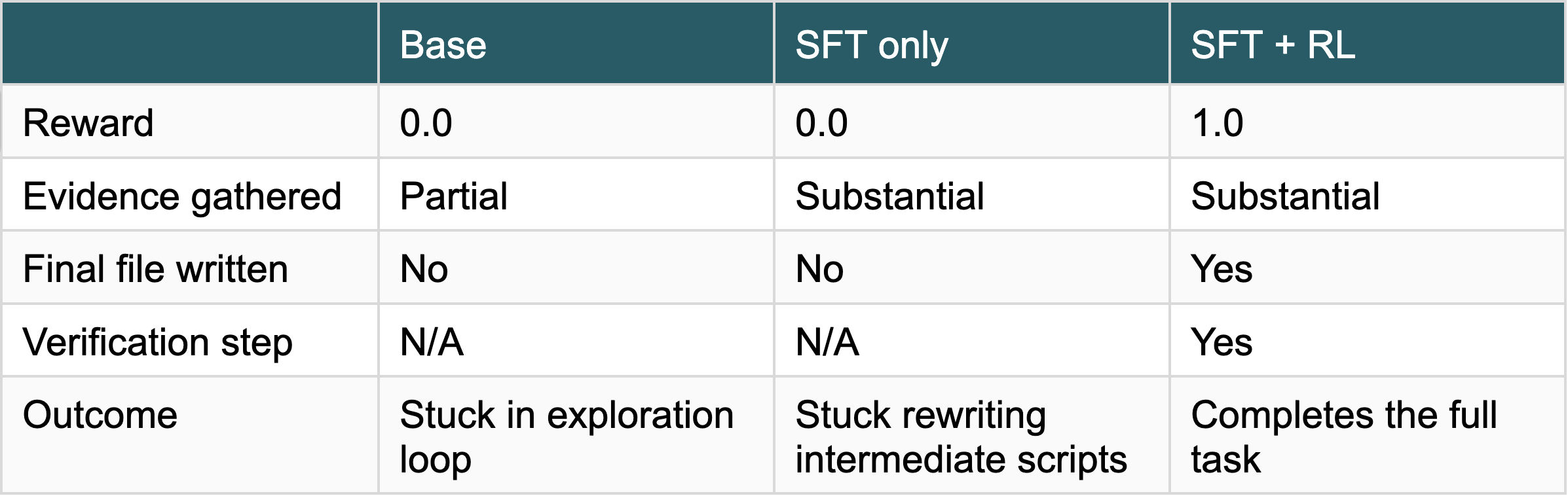
Evidence gathering is present in all three checkpoints; the differentiating behavior is execution discipline — namely, producing the required output artifact rather than terminating after intermediate analysis.
Conclusion
The value of an RL environment for post-training is determined by whether the capabilities it teaches transfer to benchmarks beyond its own task distribution. We evaluated this property directly by training on our Long-Horizon Multi-Tool Agent Tasks, one of our long-horizon RL environment suites, and measuring on three external benchmarks (Toolathlon, τ²-Bench, BFCL-V4) disjoint from the training set, with the in-distribution holdout serving as a training-pipeline check rather than the primary measurement.
Our trained model performs within approximately 1pp of GPT-5.5 (medium reasoning) on two of three external benchmarks at pass@1 and shows positive improvement on the third. A full technical paper with detailed ablations, training dynamics, and per-category trajectory analyses will follow.






