


Human-AI Alignment
In many ways, alignment – getting models to align themselves with what we humans want, not what they think we want – is the fundamental problem of AI.
- We try to build nuanced classifiers of toxic speech, for example – but they unwittingly become mere profanity detectors instead.
- Facebook trains its News Feed on engagement, to connect us with our friends and family – and inadvertently becomes a wellspring of hate speech and misinformation.
In a similar vein, while language models mostly improve their abilities as they become larger, there exist “inverse scaling” tasks where the opposite occurs: language models degrade on certain applications as they increase in size.
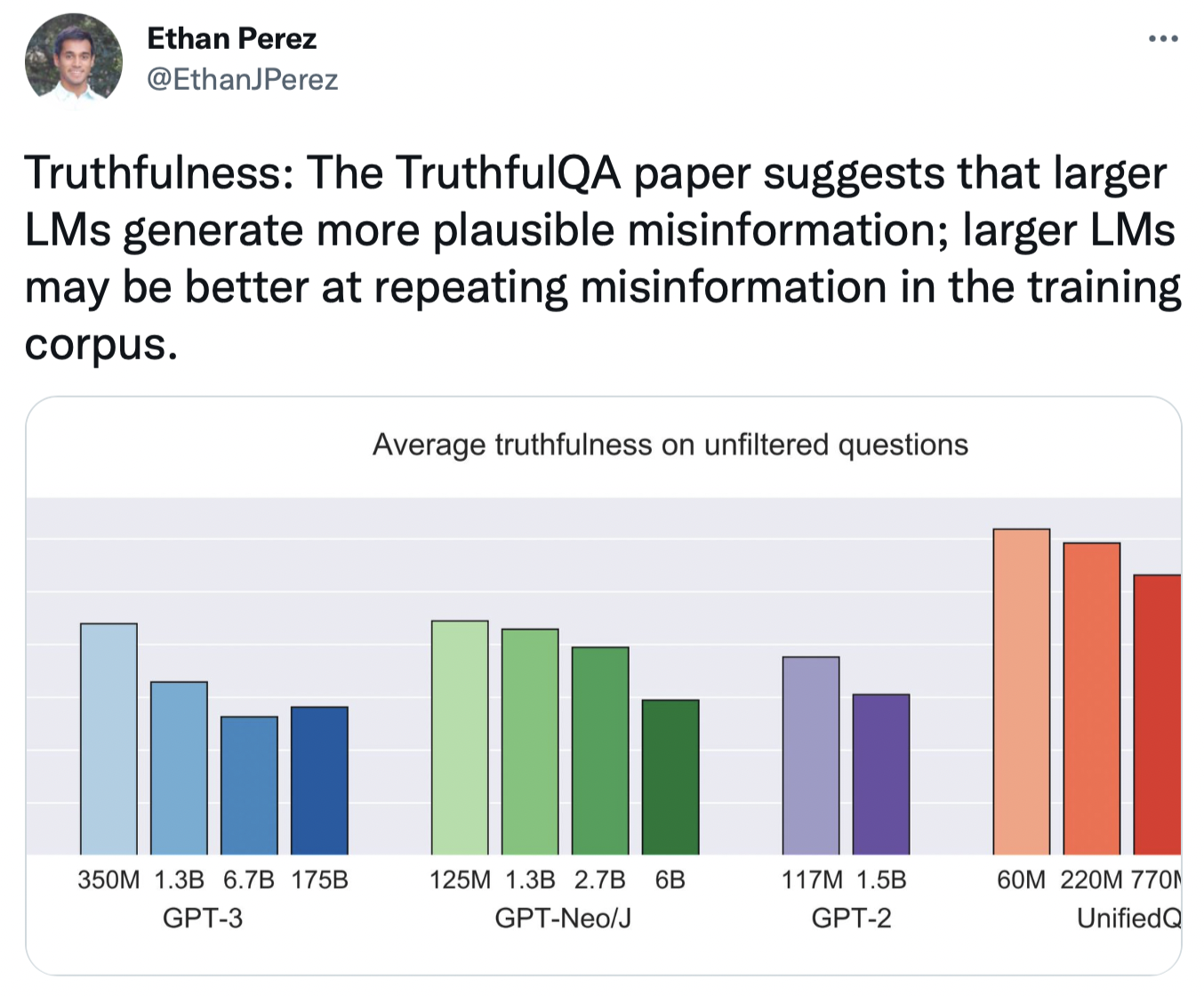
Just as optimizing for clicks doesn’t produce a News Feed we’re delighted to see, predicting the next word in a sentence isn’t quite aligned with human goals! For example, researchers have found that as models scale up, they also become more susceptible to popular misconceptions.
Why does this happen? Large language models today are trained on a specific objective: reproducing the distribution of text on a massive dataset scraped from the Internet. However, this training objective isn’t infused with the goals of the people creating language models, such as behaving in helpful, honest, and harmless ways.
Your phone’s autocomplete algorithm doesn’t have a sense of honesty either! If Flat Earth FAQs are the only websites on the Internet that answer “Why is the Earth flat?”, what do you think the most powerful autocompletion models in the world, trained to predict and mimic Internet language, would do?
Inverse scaling tasks highlight this misalignment. By uncovering more examples, the hope of the $250K Inverse Scaling Prize is to make language models safer and more reliable in the future. For more details on the contest, see Ethan Perez’s tweet thread.
Why Does Inverse Scaling Happen?
Where could we start digging to find new inverse scaling laws?
Let’s go back to why inverse scaling happens: it’s all about the data and objectives. Language models are trained to predict the next word in a piece of text – not to “answer questions truthfully” or to “classify content correctly”. And when they’re trained on the Internet, rich as it is with messiness and flaws – think of 8chan, or the amount of malformed HTML you wrote in high school, or simply the difficulty of building good scrapers – an optimization function of predicting the next word can be especially problematic.
For example, here’s a page from the Internet. Would you trust an AI model that learns from it? (Would you trust a human?)

4chan may be filtered out of the datasets most LLMs are trained on, but there may be less obvious examples. Just as AI models trained on doctors of the 18th century would believe in the power of leeching, what biases do LLMs learn from the Wild West of the Internet?
Thinking deeply about where these datasets (Internet scrapes) and objectives (next word prediction) can go wrong should inspire new ideas.
Examples of Inverse Scaling Tasks
What are some existing areas where researchers have found inverse scaling properties? Here’s a thread from Ethan with great examples.
Social Biases

Misinformation
Buggy code

Prompt Sensitivity

Personally Identifiable Information

Toxicity

Getting Started with the Inverse Scaling Prize
Interested in submitting an entry, but not sure where to start?
The Inverse Scaling Prize Github page has links to notebooks that can be used to run experiments, and the Slack group has a “things someone should try” channel where the community has been brainstorming fruitful tasks. Here are some more examples – hat tip to Ethan!
- Similar to how larger models are more likely to generate toxic text, are larger models more likely to generate advertisements or other forms of spam?
- Language models are trained on billions of web pages, and typically are concatenated via a special “end of document” token during the training process. Do larger models learn to reason across documents, and if so, does this produce any strange behaviors that could lead to inverse scaling?
- Language models extrapolate from their own outputs, and can sometimes get stuck repeating themselves in endless loops. Is this more likely to happen with larger models?
- Do language models exhibit some of the same cognitive biases demonstrated by humans?
Here’s also a reminder of the general process for creating a contest submission:

Update from Round 1!
Update (Monday, September 26): the prize is running in two rounds, and there's still time to submit for Round 2 and win the $100K grand prize! Here's an update from Ethan's tweet thread on the winners of Round 1!
Sensitivity to Negation

Incorporating New Information at Inference Time

Following New Instructions Over Memorization

Spurious Correlations


We’re excited for Surge AI to partner with NYU and the Fund for Alignment Research on the Inverse Scaling Prize! Have you found a task with LLM inverse scaling properties, but need help creating a dataset of 300+ examples for your submission? We’re a human alignment platform with deep expertise in training large language models on human feedback, and we’re here to help – including free data labeling credits to kickstart your submission.
We love working with researchers on thorny issues around human-AI alignment. If you’d like to jam on your submission dataset, or any other aspect of the Inverse Scaling Prize, let’s flip the tables together. Say hello at hello@surgehq.ai or DM us on Twitter at @HelloSurgeAI!

Data Labeling 2.0 for Rich, Creative AI
Superintelligent AI, meet your human teachers. Our data labeling platform is designed from the ground up to train the next generation of AI — whether it’s systems that can code in Python, summarize poetry, or detect the subtleties of toxic speech. Use our powerful data labeling workforce and tools to build the rich, human-powered datasets you need today.




